分布式数据库概述
分布式系统的背景,架构,分布式存储和事务.
概述
背景
现代的互联网产生了新的需求,一些大规模互联网业务(如电商,证券交易等)需要数据库满足
- 大数据:数据量超出单台机器存储容量与计算能力的上限;
- 高并发:海量用户并发请求,超出单机的带宽和处理能力上限;
- 高可用:许多场景下要求系统不会因为少量故障导致服务中断。
为了解决单点数据库的以上问题,诞生了分布式数据库:分布在多个计算机节点的、逻辑相互关联的数据集合,计算机节点之间通过网络连接进行通信,作为一个整体对外提供数据存储与查询等服务。
- 高并发性:多节点可同时响应客户端,实现多节点的并发;
- 高可扩展性:节点数量可高效扩展;
- 高可用性:即使部分节点故障,系统整体也可正常运行。
分布式数据库架构
这部分架构没太理解也没关系,可以把分布式副本一致性算法和分布式事务理解了再回来看。
一主多备,一写多读
- 主节点提供读写,
- 备节点只读。
主节点通过向备节点同步redo日志,来保证数据的一致性。
因为事务在不同机器上的执行顺序不同,所以不能在主备上同时执行事务,防止数据不一致.
多数数据库执行重做日志后,通过一致性协议即可验证事务的执行成功。
为什么写入需要一致性协议: 如果等待所有备机的写入,将出现木桶效应,即最慢的机器将会更大地影响写入的性能。
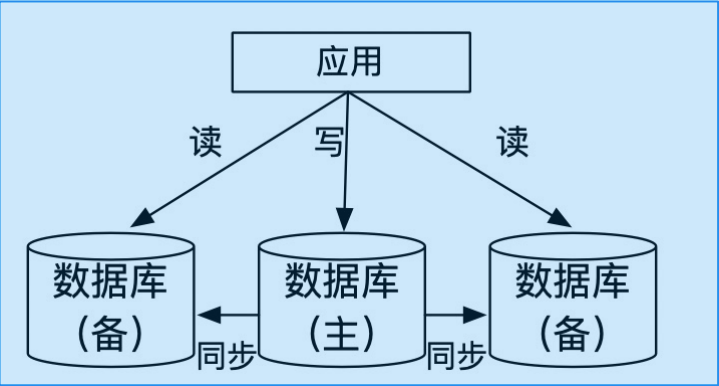
一主多备架构
多主多写(集群式)
每个数据库节点都持有数据库的一部分分片,并支持本节点上数据的读写。 如果在一个节点上读写其他节点的数据,那就需要从其他节点同步数据到本节点上。 数据量大的时候,扩展性比较差。
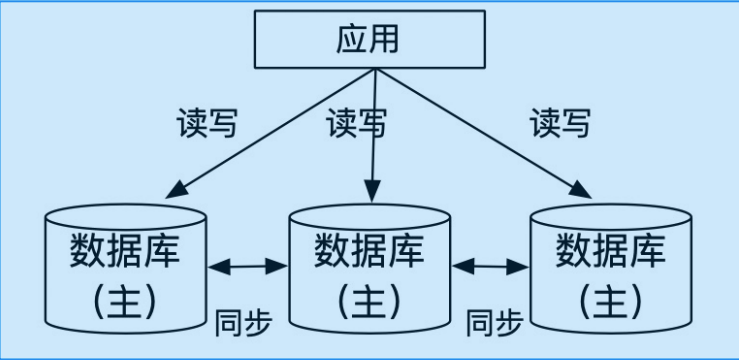
多主多写
分库分表中间件
搭建于多台单机数据库之上,通过中间件负责SQL转发和结果汇聚。 问题:
- 中间件只处理了分库分表和转发,很难去做并发控制
- 做不了强一致性(实时一致性)。没有全局时间戳,每个数据库节点时间戳都不一致。
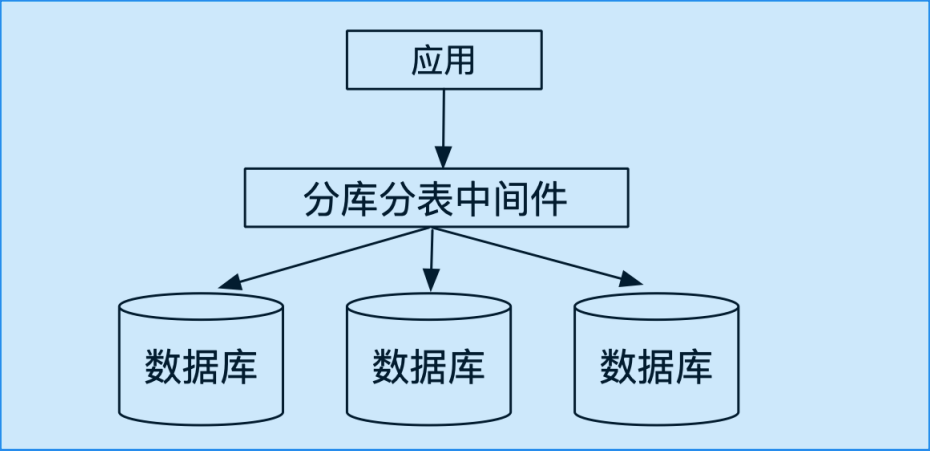
分库分表
原生分布式数据库
节点间无共享架构,shared-nothing,分片间多写多读。每一个分片类似一主多备,一写多读的形式。
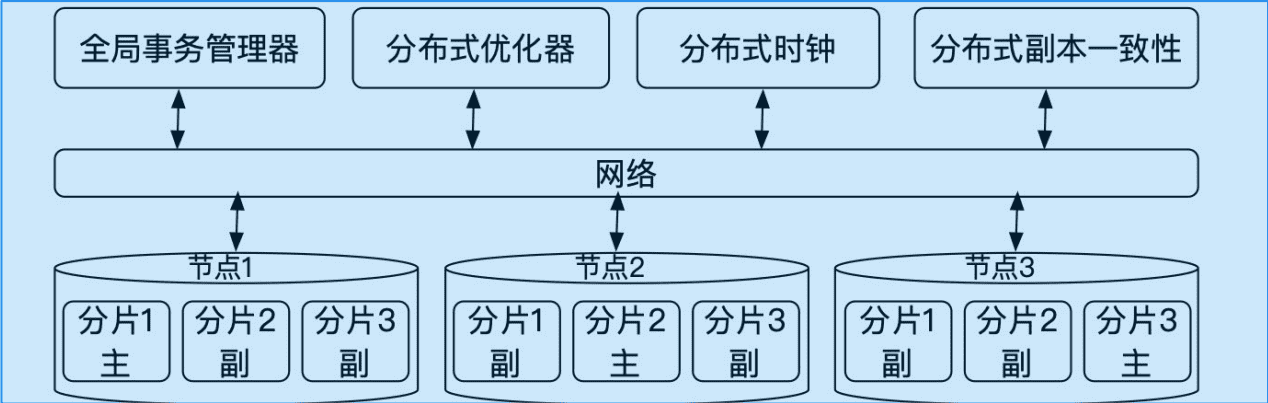
原生分布式
对比
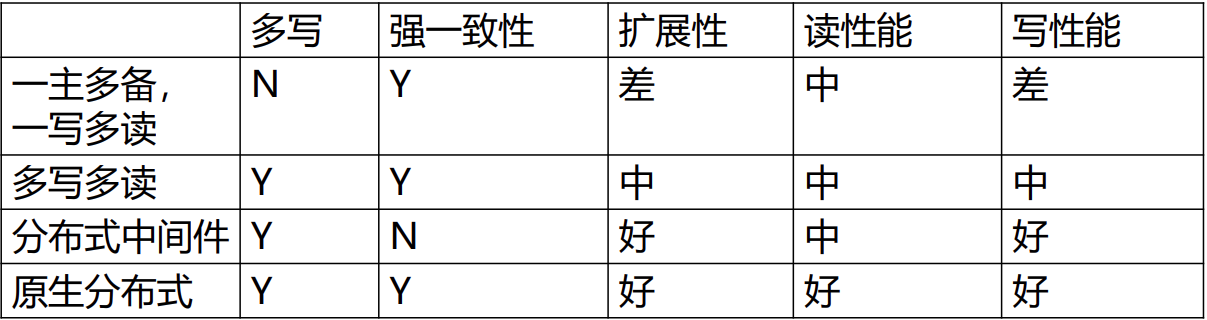
不同架构对比
- 原生分布式:shared nothing,数据分片,计算移动;
- 多写多读集群式:shared storage,页面划分,数据移动;
- 分布式中间件:不支持强一致,需要中间件分发和汇总 。
分布式数据库的ACID
- 持久性:实现与单机数据库的实现方法基本相同;
- 一致性:副本一致性通过Paxos、Raft等一致性协议来解决;
- 原子性:分布式原子提交协议;
- 隔离性:并发控制,分布式时间戳。
分布式数据存储
数据分布式存储方式
根据表在节点内以及不同节点间的数据分布,将表分为:
- 单节点表:只存在于单个访问节点的表,例如表C;
- 复制表:每个节点都存储完整副本的表,例如表B;
- 多分片表:数据划分不同分片,每个节点存储一个分片,例如表A。
下图展示了在云原生数据库架构下的不同类型的表的数据分布:
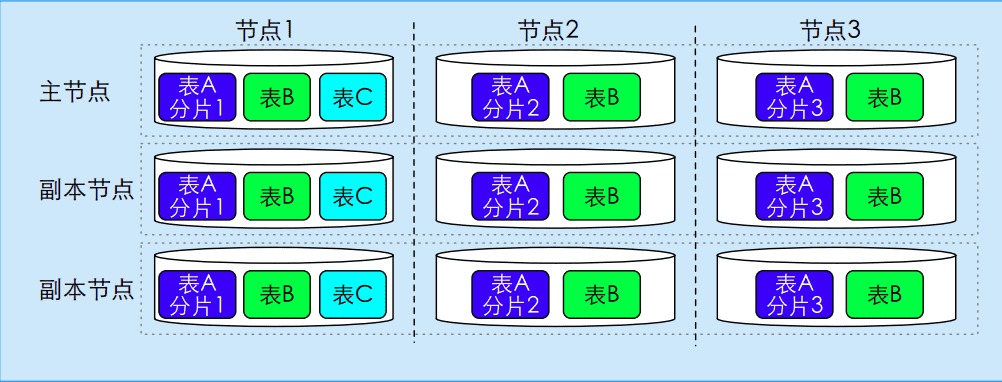
表的数据分布
分布式存储方式对比
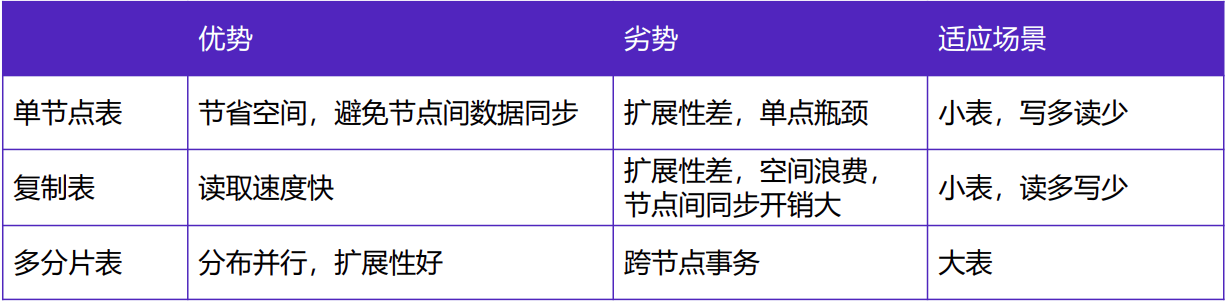
不同分布方式对比
数据分片
- 数据切分为多个分片,存储在不同节点,每个节点存储1个或多个分片;
- 分片类型:
- 水平分片:按行切分,不同的行存储于不同节点;
- 垂直分片:按列切分,不同的列存储于不同节点。
- 水平分片算法:
- 哈希分片Hash:将每条记录在分布列(控制数据的分布)的哈希值相同的数据记录分到相同节点;
- 范围分片Range:根据每条记录在分布列的值进行范围划分,将同一范围内的数据记录划分到相同节点,例如按照学号;
- 列表分片List:根据每条记录在分布列的值进行列表划分,即将该分布列的所有值进行分组,落在相同分组的数据记录放到同一个节点,例如按照省份。
多副本和一致性
- 每个数据分片以多副本形式存储在多个节点中;
- 防止由于单个节点故障造成数据损坏或丢失的情况,节点故障会从副本中选举出一个可用版本;
- 提高了系统可用性与吞吐量。
副本更新的一致性问题
当数据更新时,由于其只更新了一个副本而将更新数据同步至其他副本的过程往往存在一定延时,会导致同时读取不同副本的数据时可能会得到不同的值。 故在副本间需要通过一致性协议确定可用副本。一致性协议包含:
- 多数派:Paxos、Raft
- Quorum:R+W>N。R:进行读操作的机器,W:进行写操作的机器,N:有多少机器;R+W>N保证有机器既读又写。
分布式事务
分布式原子提交
- 分布式原子提交 vs 单节点提交
- 单节点只有一个参与方;分布式有多个参与方;
- 事务在所有节点中的操作要么全部执行要么全部不执行。
- 分布式原子提交方法:
- 两阶段提交(2PC);
- 三阶段提交(3PC);
- Calvin。
- 参与事务处理的节点:
- 事务协调者:与参与者通信,协调与调度事务;
- 事务参与者:即数据存储的节点,执行事务在单节点中的操作。
两阶段提交(主流)
将分布式事务分为两个阶段:
- 准备阶段:
- 协调者询问参与者是否可以提交;
- 参与者判断自身是否可以提交,并向协调者发送是否可以提交的消息;(此步骤需要上锁)
- 参与者执行事务操作,记录日志。(此步骤需要写日志,用以进行回滚和同步数据)
- 提交阶段:
- 如果所有参与者都可以提交,则协调者发送提交指令;
- 如果任何一个参与者无法提交,则协调者发送回滚指令;
- 参与者收到指令后进行提交或回滚操作。
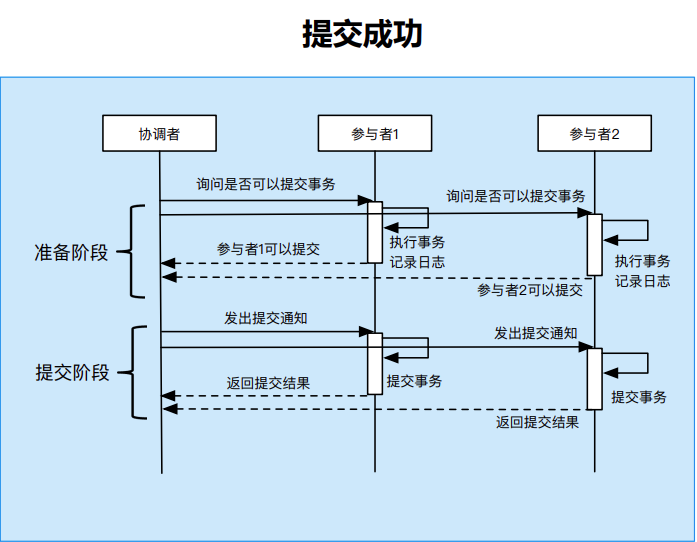
2PC提交成功
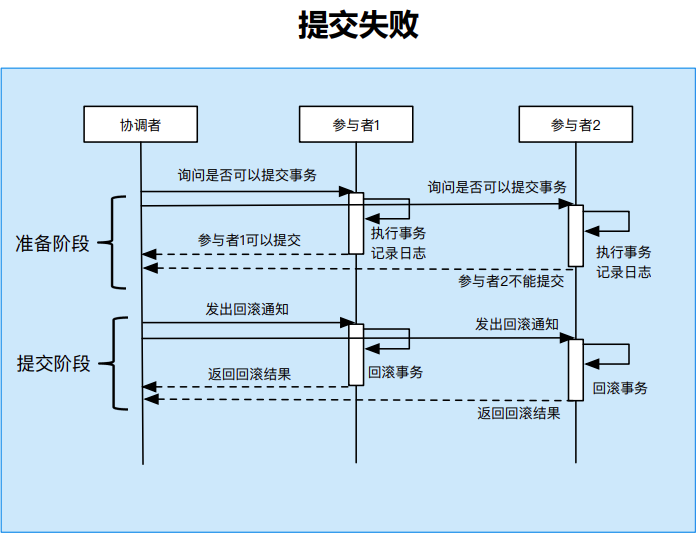
2PC提交失败
两阶段提交的问题:
- 性能较差
- 准备阶段协调者需要等待所有参与者回复(执行完事务工作单元)才能进入提交阶段;
- 准备阶段存在加锁操作,影响系统性能。
- 单点故障
- 协调者发生故障时会影响所有参与者;
- 若提交阶段协调者故障,所有参与者都会阻塞。
- 数据不一致风险
- 提交阶段协调者发送提交指令后出现网络故障,导致部分参与者收到提交指令而其他参与者没有收到提交指令
当下主流的分布式数据库处理方式都是2PC+Paxos,使用2PC处理多个分片间的分布式事务,使用Paxos解决分片故障的多副本选举问题。
三阶段提交
三阶段提交对两阶段提交的问题进行了改进,具体体现在:
- 针对性能的问题,三阶段提交在准备阶段和提交阶段之间添加预提交阶段;准备阶段不加锁,提升性能;预提交阶段参与者执行事务单元。解决了准备阶段需要加锁的问题
- 针对单点故障的问题:
- 协调者将准备阶段的投票结果发送给所有参与者;
- 协调者故障后,新的协调者根据参与者记录的投票结果判断提交还是中止事务;
- 解决协调者单点故障带来的阻塞问题。
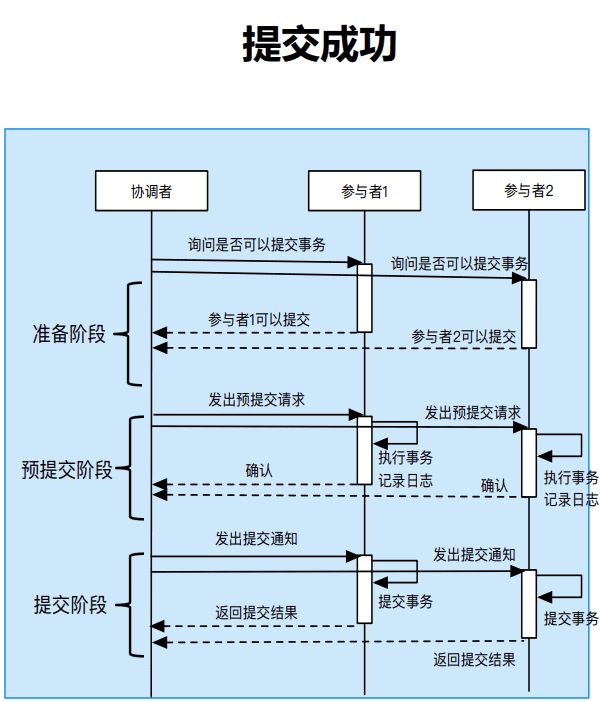
3PC提交成功
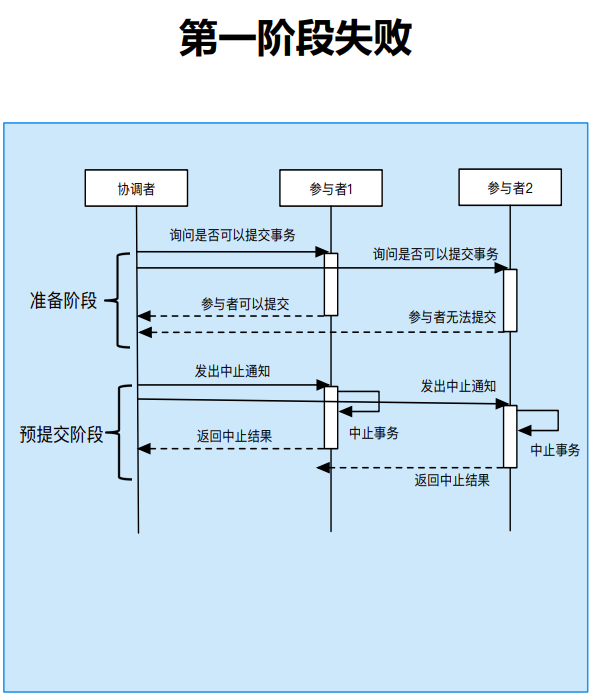
3PC第一阶段提交失败
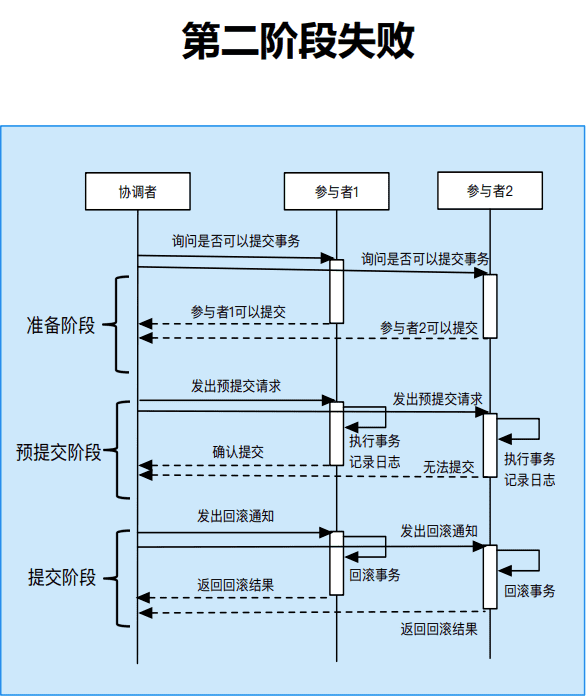
3PC第二阶段提交失败
三阶段提交的问题:
- 通信代价高,性能差。(因为要经过三轮网络IO)
- 数据不一致:
- 预提交阶段发生网络分区。
- 收到预提交请求的节点和协调者位于一个分区,未收到预提交请求的节点位于另一分区;两个分区分别进行事务提交和事务中止,造成数据不一致。 网络分区下数据不一致的情况,每个分片的多副本需要使用Paxos(或者其他)选举新的可用副本。
Calvin
Calvin用于处理确定性的事务(指各节点事务顺序保持一致)。要求事务运行之前确定读取集和写入集,并在执行前定序,在执行之后需要进行时钟的对齐。 降低节点之间协调的通信开销:无需像两阶段提交和三阶段提交一样进行多轮通信,可以提高事务吞吐量。
其实也就差不多是节点间请求的按序流转。(是吧)
并发控制
如果要展开了解并发控制,可以阅读这篇文章。
- 基于锁的方法(参考悲观并发控制):
- 集中式锁管理器:实现简单,但锁管理器容易成为系统的性能瓶颈,且存在单点故障。
- 分布式锁管理器:解决了单点故障和瓶颈,但死锁检测比较复杂。
- 基于时间戳的方法(参考乐观并发控制):
- 集中式时间戳:授时中心称为性能瓶颈,且单点难以实现高可用。
- 分布式时间戳:高可用,但时钟顺序维护较为复杂。
时钟
分布式系统中可以使用时间戳来实现并发控制,而时钟系统正是用于生成时间戳。如果要展开了解分布式系统中使用的时钟,可以阅读这篇文章,本篇略。
锁
如果要展开了解分布式系统中使用的时钟,可以阅读这篇文章,本篇略。
后台开发中也经常提到分布式锁,但和这里的分布式锁不一样。后台开发的分布式锁指的是后台分布式系统的锁,既有可能是是集中式的锁,也有可能是分布式的锁。这里的分布式锁指的是锁管理这个系统本身就是分布式的。
分布式查询优化
前面的分布式数据存储和分布式事务其实很多技术会用到后台开发的服务架构设计上,与数据库不同的是不同的业务需要对后台服务的要求不同,可能在很多方面做不同的权衡决定。
对于后台开发来说,大部分业务的代码会比数据库的业务代码(可以理解为数据库的业务代码就是负责增删查改语言的执行和优化)复杂得多(也可能简单得多),这里主要学习一下查询优化上的设计哲学。
分布式查询优化原则:
- 尽量减少跨节点数据交换;
- 利用分布式存储的特性进行并行化的查询优化和执行,尽量并行计算(MPP,SMP,SIMD,多机并行,多线程并行,单指令多数据处理)进行分片剪枝。
这篇文章会展开了解分布式的查询优化(主要是分布式表连接的优化)。