分布式锁
分布式锁的介绍以及实现
概述
在单机环境下,锁常用于控制不同线程/进程之间对贡献资源的访问。而在一个分布式系统中,分布式锁则承担不同的节点的进程之间对共享资源的访问控制,保证在同一个时刻仅有一个访问可以调用共享资源。
集中式和分布式
分布式锁的实现根据节点数量分为两种:
- 集中式:有一个单点的服务提供分布式锁的服务,实现简单,但锁管理器容易成为系统的性能瓶颈,且存在单点故障;
- 分布式:有一个分布式的锁服务提供分布式锁,解决了单点故障和瓶颈,但死锁检测比较复杂;
但是就实际情况来说,如果容灾要求不那么高的话,就分布式锁的数据量一般都不需要太多节点。
实现
分布式锁的实现根据常用的方案可以分为:
- 基于数据库的分布式锁;
- 基于Redis实现的分布式锁;
- 基于Zookeeper的分布式锁。
其实在本质上都是基于数据库存储,文中将详细展开每种实现方式,并对比其优劣之处和适用场景。
在功能上,一般来说分布式锁需要实现上锁和解锁两个接口,类似于单机上的互斥锁。但是分布式系统中,常常会出现 请求丢失,网络故障,延迟,甚至节点失效等问题,这要求分布式锁需要具备条件:
- 与单机系统一样的资源互斥功能,这是锁的基础;
- 高性能获取、释放锁;非阻塞,不管是否获得锁,要能快速返回。
- 高可用;
- 具备可重入性,即一个服务节点可以多次发送加锁请求来加锁,以防止网络故障,延迟等问题接收到多个同一节点的加锁请求而拒绝服务;
- 有锁失效机制或者死锁检测,防止死锁;一般还是采用锁超时的机制,因为分布式的节点是不是会有宕机的。
分布式死锁检测
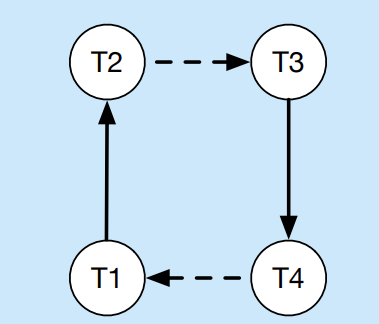 在一个分布式系统中,如果存在多个节点,使用分布式锁时发生死锁通常难以从日志以及堆栈中发现,因此如果需要对分布式死锁进行跟踪检测,需要添加分布式锁的检测服务。
在一个分布式系统中,如果存在多个节点,使用分布式锁时发生死锁通常难以从日志以及堆栈中发现,因此如果需要对分布式死锁进行跟踪检测,需要添加分布式锁的检测服务。
在分布式系统中,每个节点构建自己的事务等待关系(等待的节点,等待自己的节点),然后汇总到一起构建分布式的优先图。和单机一样,优先图带环则死锁。正常的情况应该是一个有向无环图。
比如图中,箭头指向表示自身节点等待的事务,如果四个节点间产生了环,则会陷入无休止的等待(死锁)中。
Redis
集中式分布式锁(单点提供锁服务)
Redis下可以通过插入数据项来实现分布式锁:
- 申请加锁:如果表里没有指定数据项,添加数据项,加锁成功;如果有,加锁失败。
- 申请解锁:从表中删除指定数据项
- 锁过期:申请加锁时指定数据项的过期时间。
为了加锁和设置过期作为一个原子化操作,可以这样:
1
SET lock $uuid EX 20 NX
问题:
- 跟单机的锁超时重启机制一样,难以合理设置等待时间(因为事务的执行时间以及需要的锁的数量一般是未知的);
- 需要防止非加锁服务的解锁请求解开锁,即需要保证加锁-过期-解锁过程原子。这个过程可以由加锁方发送Lua脚本,由redis服务器根据lua脚本判断锁是自己加上的来实现。
- 集中式锁的相同问题:容易出现单点故障,可用性收到影响。
Redis 作者也设计了一个分布式锁 Redlock,直接调用的方式放在了Java SDK Redisson中。
Redlock(红锁)
按照主备的方式部署Redis的话,申请加锁中难免会因为延迟而导致主服务节点加上锁而备服务器没有加上锁的情况,导致数据不一致。
Redlock实现基于2个前提:
- 不需要部署从库和哨兵实例,只部署主库;
- 主库要部署多个。
整体的流程分为5步:
- 客户端获取当前时间戳T1;
- 客户端依次向这些Redis实例发起加锁请求(用前面讲到的SET),且每个请求设置超时时间(毫秒级,要远小于锁的有效时间),如果某一个实例加锁失败(包括网络超时,锁已经被持有等各种情况),就立即向下一个Redis实例申请锁;
- 如果客户端从大多数(一半以上)Redis实例加锁成功,则再次获取当前时间戳T2,如果T2-T1<锁的过期时间,此时认为客户端加锁成功,否则认为加锁失败。
- 加锁成功,去操作共享资源。
- 加锁失败,向全部节点发送释放锁请求(上文提到的Lua脚本)。
按我的观点,Redlock就是依托答辩,确实很多问题。
- 作者推荐是5个节点或者以上,太重了;
- 时间戳可能产生漂移;
- 你这也妹实现锁之间的严格互斥啊,设置的超时时间这么短的话,有其他服务拿到锁了那不就竞争了。
对比单Redis做分布式锁,机器更多更重,但是为了解决单点故障搞得设计它自身安全性又不够。垃圾👎!浪费我半小时时间!这种东西放在Java SDK里到时又很多人不明不白地调用了。
我觉得要么就牺牲一点性能,解决单点故障的问题但保证安全高可用;要不就冲着高性能去,单点提供锁就完了。至于如果锁的量太大机器的带宽/容量/处理器性能不满足需要扩展(真的有这种业务吗?),直接水平扩展或者集群模式就完了。
比较搞笑的是,作者后面也觉得Redlock确实没啥卵用,后面版本就把它拿掉了。
zookeeper
Zookeeper主要负责的是集群管理,它负责管理服务提供方的ip地址端口号、url信息,并在服务消费方请求时发送给服务消费方。集群管理可以包括集群的监控、退出和加入节点、选举Master等功能。使用Zookeeper实现分布式锁的操作:
- 加入节点A和节点B都要申请同一个资源的锁,向Zookeeper申请创建临时节点;
- 加入A先到达,则加锁成功,节点B加锁失败;
- 节点A操作资源;
- 节点A删除临时节点,释放锁。
其中,Zookeeper没有设置过期时间,通过节点与Zookeeper维护一个Session,节点向Zookeeper发送定时心跳来维持连接。只有主动释放和心跳异常两种情况释放锁。
Zookeeper实现分布式锁的优点:
- 不用考虑锁的过期时间;
缺点:
- 性能不如Redis,心跳频率太高性能差,太低了获取锁效率差;
- 部署维护成本高;
- 客户端如果拿到了锁但是中途失联,锁会被主动释放。
基于数据库的实现
Mysql
普通表实现
使用Mysql创建一张锁表,然后通过对缩表的数据来进行插入删除,即可实现分布式锁的方法。如果数据库已有数据条目,重新上锁就会因为主键唯一的约束拒绝上锁,从而达到互斥的目的。解锁则直接将数据条目删除即可。在数据条目中加入上锁的服务的节点信息,获取锁的时候检查是否能查询到已上锁,类似地实现锁可重入(算是曲线救国了)。
缺点:
- 锁依赖数据库的可用性,如果需要高可用的话需要有数据备份;
- 没有失效时间,如果要实现锁超时失效机制,需要使用锁的服务层自行实现定时主动删除;
- 只提供了非阻塞的加锁方式,如果需要阻塞式的加锁方式需要轮询实现。
排他锁实现
由于Mysql的InnoDB支持行级排他锁,可以使用排他锁来实现分布式锁,对数据条目获取排他锁视为分布式锁上锁成功。数据库宕机之后会自己把锁释放掉,且可以通过阻塞等待排他锁来实现阻塞请求锁。但是仍然存在不会主动释放锁/不可重入/单点的问题。
Mysql实现数据库其实还是挺偷懒的做法,有点丑陋,建议不用。(不过也好过不用分布式锁)