Exploiting Cloud Object Storage for High-Performance Analytics
慕尼黑工业大学(TUM)2023 年 7 月发表在 PVLDB 的论文: 利用对象存储进行高性能数据分析
ByteHouse,Greptime都借鉴了该论文的设计。原文参考这里。
abstract
弹性计算和存储对分析性云原生数据库系统至关重要。原本由于网络IO的延迟,不可避免地需要处理本地的大量数据。但随着NVMe和网络IO性能的接近,云存储更适合存储大量数据。
本文提出了依赖云存储的分析型数据库的架构。为了实现高性能的检索,本文提出了AnyBlob,一个用于新型的下载管理器,用于优化查询引擎的吞吐量,降低CPU的使用率,并在数据库系统Umbra中演示之。
Introduction
云对象存储存储几乎无限容量,且可以保证极高的数据可用性。2018年之后AWS推出了100 Gbit/s(≈12GB/s)带宽的对象存储,缩小了与NVMe的带宽差距。这对实现带宽依赖为主的数据应用(分析型业务)尤为重要。
这里的 Gbit/s 与 GB/s 之间是 bit 与 Byte 之间的换算。
文中认为有三个挑战:
- 充分利用(achieving)带宽:因为单对象的请求延迟较高,要使高带宽网络达到饱和状态需要许多并发请求。因此,DBMS需要非常谨慎地设计网络读写方式才可以充分利用网络优化实例上的可用带宽;
- 存在网络CPU额外开销:与从本地磁盘获取数据相比,网络检索有更高的 CPU 开销。
- 多云支持:许多云数据库系统能够在不同的云平台上运行,允许用户选择他们喜欢的供应商。与多云系统的需求相反,每个云供应商都提供自己的网络库。因此,必须集成多个库,这增加了系统的复杂性。
文中总结了三个贡献:
- 云对象存储的实验研究:为了实现高带宽数据处理,文中研究了云对象存储的特性。在第 2 节中,我们解释了分离式存储的设计,讨论了其成本结构,并提供了关于不同对象存储的延迟和吞吐量的详细实验。我们定义了一个最优请求大小范围,以在最大化吞吐量的同时最小化成本。我们的并发分析有助于安排足够的请求,以达到吞吐量目标(即实例带宽);
- AnyBlob,一个高性能的多云对象存储下载管理器,专为大数据分析优化:第 3 节中描述的AnyBlob,能够在显著减少CPU资源消耗的情况下,达到与云供应商提供的库相同的吞吐量。CPU资源利用率对于并发处理数据至关重要。与现有解决方案不同,我们的方法不需要为并行请求启动新线程,因为它使用了
io_uring,这简化了异步系统调用。根据我们的分析,要充分利用网络带宽,必须同时保持数百个请求处于进行中状态。我们的解决方案有助于减少线程调度的开销,并允许与数据库查询引擎无缝集成; - 集成检索的大致框架。将下载管理器与数据库引擎紧密集成,使得在分离式存储上实现高效分析成为可能。在第 4 节中,我们提出了将AnyBlob集成到数据库引擎中的蓝图。通过精心设计的扫描操作符和开发的对象检索调度器,我们可以将对象的下载与分析处理无缝交错进行。
云对象存储特性
为了设计一个基于云对象存储的高效分析引擎,我们需要了解其基本特性。我们首先分析分离式对象存储和计算实例的性能特性及成本。
为了深入了解存储架构,我们在AWS S3和其他两家云提供商上进行了各种微实验,以理解延迟和吞吐量的限制。
对象存储产品设计架构
对象存储降数据以对象形式存储,这些对象在多个存储服务器上分布和复制,以确保可用性和持久性。在解析云对象存储的域名后,用户从存储服务器请求一个对象,该服务器随后发送数据。所有主要云提供商都使用类似的API,通过HTTP(TCP)传输数据。
国内三大云厂商(Ali/tx/hw)都是用的http.
对象存储中数据存储在类似硬盘分区的存储桶中。根据AWS的说法,S3对所有前缀进行分区,以支持每秒成千上万的请求。对象存储服务会复制数据,保证数据的强一致性,可用性和持久性。
数据访问性能受实例(和上文相同,这里指计算实例)的网络连接、云存储的网络连接以及网络本身(比如两者不在一个内网等等)的影响。在AWS,通用实例对对象存储的带宽可达100 Gbit/s及以上。
对象存储费用开销
所有云厂商采用类似的定价方式,费用分为:
- 存储空间成本;
- 数据检索和修改成本(API成本,以调用次数为计费指标);
- 区域间网络传输成本(按传输的流量计费,一般同区域的实例访问不计费)。
结论1: 对比其他产品(比如块存储,云硬盘等),对象存储的空间,持久化和可用性性价比是最好的。
延迟
不同请求大小:区分总持续时间和首次字节被检索到的延迟。仅使用单个请求的结果如图所示。我们区分首次迭代和第20次连续迭代,以模拟热访问。实验结果表明:
- 对于小请求大小,首字节延迟往往主导整体运行时间,首次字节延迟和总持续时间相似。这突显了往返延迟限制了整体吞吐量;
- 对于足够大的请求,带宽成为限制因素。从8 MiB增加到16 MiB时,我们看到改进很小,但持续时间已经增加了约1.9倍,而对象大小翻倍。从16 MiB增加到32 MiB会导致检索持续时间翻倍。
因此,达到了带宽限制,进一步增加大小对检索性能没有益处。当数据为热数据时,首次字节延迟和总延迟通常会减少。
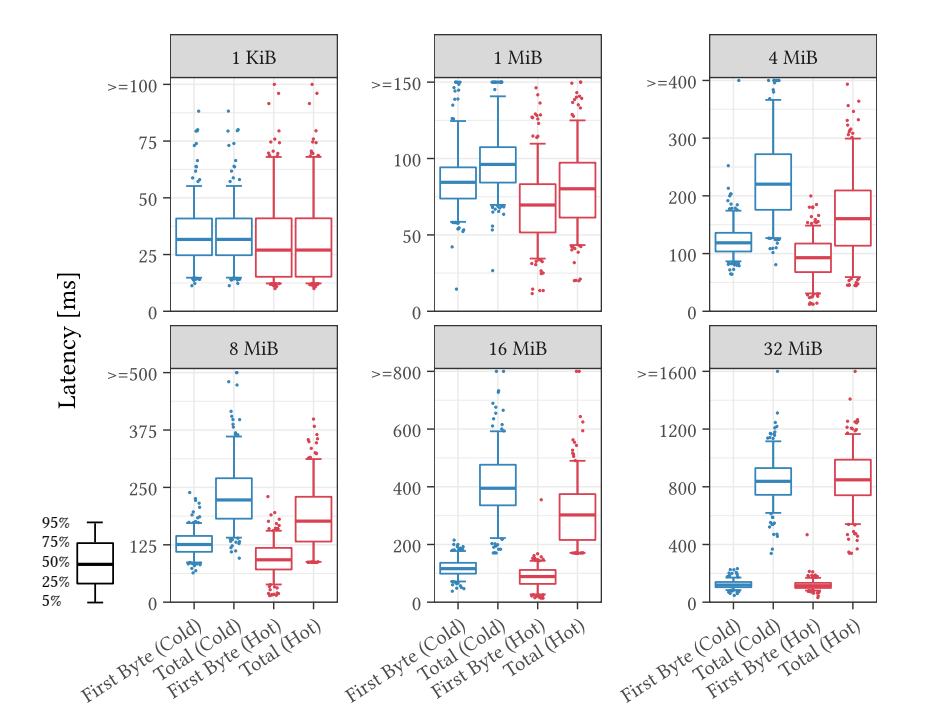 First byte and total latency for different requests sizes on hot and cold objects (AWS, eu-central-1, c5n.large)
First byte and total latency for different requests sizes on hot and cold objects (AWS, eu-central-1, c5n.large)
嘈杂的邻居:由于云存储服务于多个客户,其延迟不可预测,性能趋势表现为:
- 周末的访问速度优于工作日;
- 速度上限为95 MB/s(s3),可能是S3内部做了带宽的限制,且隐藏了S3服务端缓存的加速效果。
不同云厂商的区别:对比了另外两个云厂商的存储产品,单个文件使用16MB的文件(算是比较大的),每次请求间隔12h,实验得出结果:
- S3延迟最大;
- S3具有“最小延迟”,即每个对象的延迟都有极限速度,所有数据都比该数值高;
- 与 AWS 相比,在低延迟范围内的异常值表明其他供应商不隐藏缓存效果(AWS你坏事做尽😅!)。
S3 底层硬件和实现或许也有关系,整体硬件更老旧或者不同的缓存方案都会导致 2,3 两个情况. PS. 国外的云厂商应该可能测的是AWS, Microsoft, Google
吞吐量
OLAP业务中,更多的场景是需要处理海量的数据,该情况下带宽的影响要大于首字节延迟。
为了使用实例提供的最大带宽,实验采用单个文件 16 MiB,256 个并行请求,并选用 100Gbit/s 带宽的实例(或最大带宽)。实验表明,实例访问云存储的吞吐量:
- 随地域波动;
- AWS 75Gbit/s(接近实例的带宽), Cloud X 40Gbit/s, Cloud Y 50Gbit/s;
- 冷热数据差别不大。
小型实例允许突发,但会在消耗完突发额度之后回落到基准吞吐量。
结论2: 对象检索可以接近网络带宽。
最佳请求大小
请求大小影响:
- 费用,由于按照请求数量收费,请求越大费用越低;
- 性能,上文中表明单个请求存在带宽限制,因此请求越小,可以使用并行下载提高吞吐量。
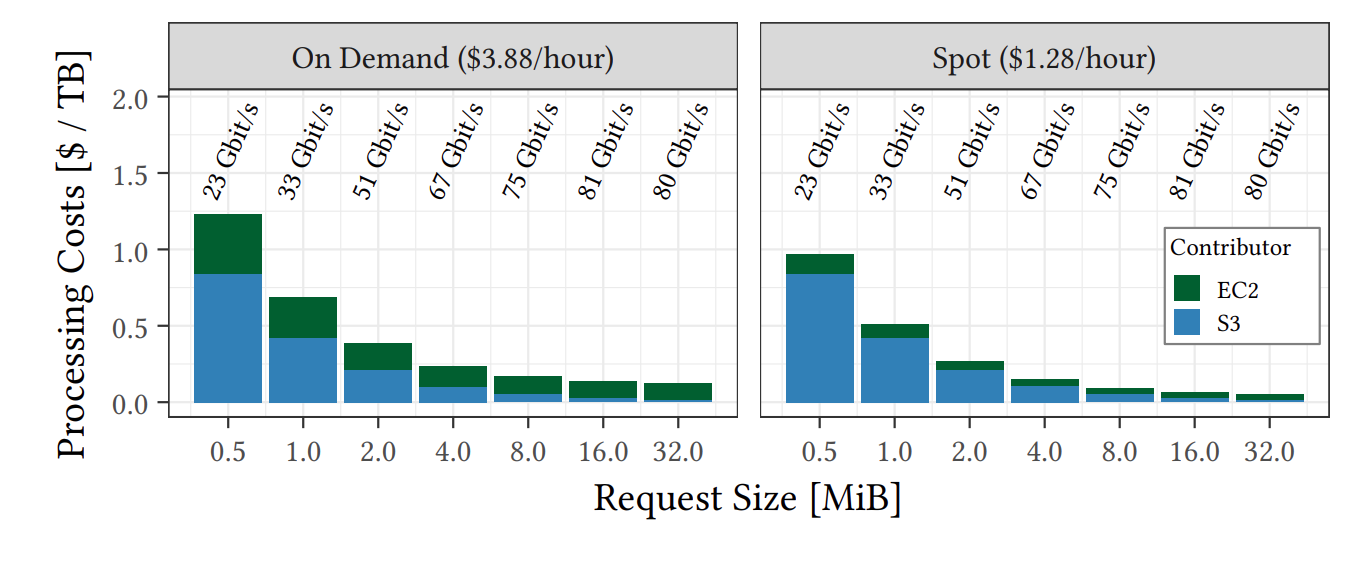 Cost vs. throughput of different request sizes (AWS, eu-central-1, c5n.18xlarge).
Cost vs. throughput of different request sizes (AWS, eu-central-1, c5n.18xlarge).
通过上图可以看出,最佳请求大小通常在 8-16 MiB。尽管 32 MiB 的价格更低一些,但在相同带宽下,其下载用时会比 16 MiB 高一倍,相比于 8-16 MiB 而言优势并不明显。
过小的请求可能是因为首字节延迟过大&&单台机器连接数量有限,因此影响吞吐量。
结论3: 兼顾成本和吞吐量的最优请求大小为 8 - 16 MiB。
加密
目前为止的实验都是用的是HTTP连接,但S3也支持HTTPS连接。使用加密连接的表现对比:
- HTTPS 需要 HTTP 2 倍 CPU 资源;
- AES 只需要增加 30% CPU 资源。
静态加密优于 HTTPS。在 AWS,区域之间的所有流量,甚至可用区之间的所有流量都会由网络基础设施自动加密。在一个位置内,由于 VPC 的隔离,没有其他用户能够拦截 EC2 实例和 S3 网关之间的流量,从而使 HTTPS 变得多余。但是,需要静态加密来确保实例外部(例如,在 S3)的完全数据加密。
慢请求
存在一部分存储服务器的响应请求或者缓慢,造成相当大的尾部延迟(Tail Latency)。为了应对这种情况,云供应商建议采用重新请求无响应的请求(request hedging)策略。
作者得到了一些慢请求的经验值,对于 16 MiB 大小的文件:
- 在经过 600 毫秒后,只有不到 5% 的对象尚未被成功下载;
- 第一个字节的延迟超过 200 毫秒的对象也不到 5%。
- 基于上述经验值,可以考虑对那些超过一定延迟阈值的请求进行重新下载的尝试。对这些请求进行对冲不会带来显著的性能开销。
云存储检索模型
为了充分利用网络带宽,需要大量并发请求。对于分析型工作负载而言,8-16 MiB 范围内的请求是具有成本效益的。他们设计了一个模型,用于预测达到给定吞吐目标所需的请求数量。
\[requests = thoughtput \cdot \frac{baseLatency + size \cdot dataLatency}{size}\]使用S3的情况下:
- baseLatency 的中位数约为 30 ms(由上文中1KB的请求得出);
- dataLatency 的中位数约为 20 ms/MiB,Cloud X 和 Cloud Y 更低 (12–15 ms/MiB) (由 16 MiB 中位数 - 基本延迟得出);
- 带入模型中,得到 S3 跑满 100 Gbps 需要 200-250 个并发请求;
- 数十几毫秒的访问延迟和单个对象的带宽约为 50 MiB/s,对象存储应该是基于 HDD 的(意味着以 ∼80 Gbps 从 S3 读取相当于同时访问约 100 个 HDD)。
由实验结果也可以看出,基本数据请求数量和带宽的关系与模型相近,而在接近 S3 带宽上限开始限制带宽。
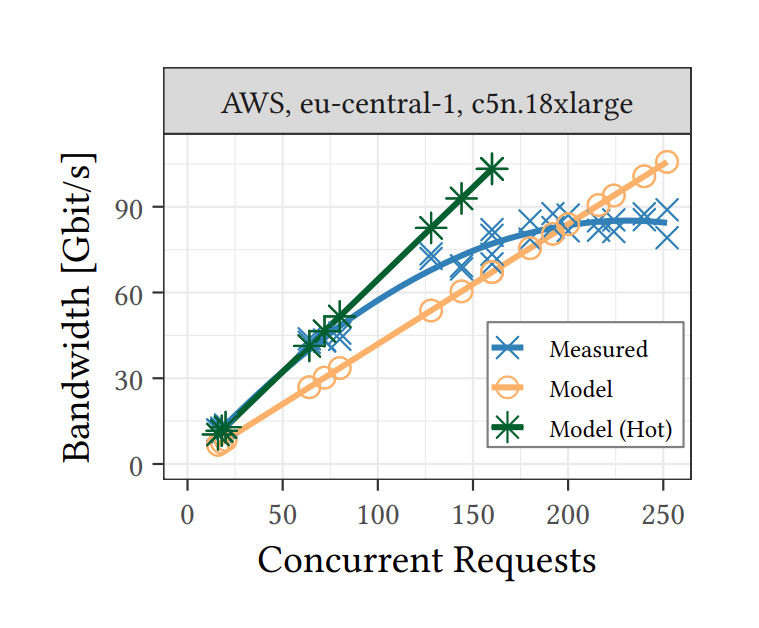 Request modeling for reaching throughput goal
Request modeling for reaching throughput goal
结论4: 使高带宽网络达到饱和需要向云对象存储发出数百个未完成的请求。
AnyBlob
AnyBlob 是作者自行设计的通用对象下载器,支持访问不同云服务商的对象存储服务。AnyBlob 采用了 io_uring 接口,使用更少的CPU资源。现有的下载库为每个并行请求启动新线程。例如,AWS SDK的S3下载管理器使用开源HTTP库curl,每个线程执行一个请求。与为单个请求启动线程不同,AnyBlob使用异步请求,这使我们能够调度更少的线程。
最终结果显示 AnyBlob 有着更高的性能并且 CPU 使用有所降低。
也可能就是现有 C++ S3 库质量太差了。
Design
AnyBlob使用io_uring实现每个线程异步管理多个连接,减少额外的调度成本。接下来介绍AnyBlob的三个组件,组件间的关系如图。
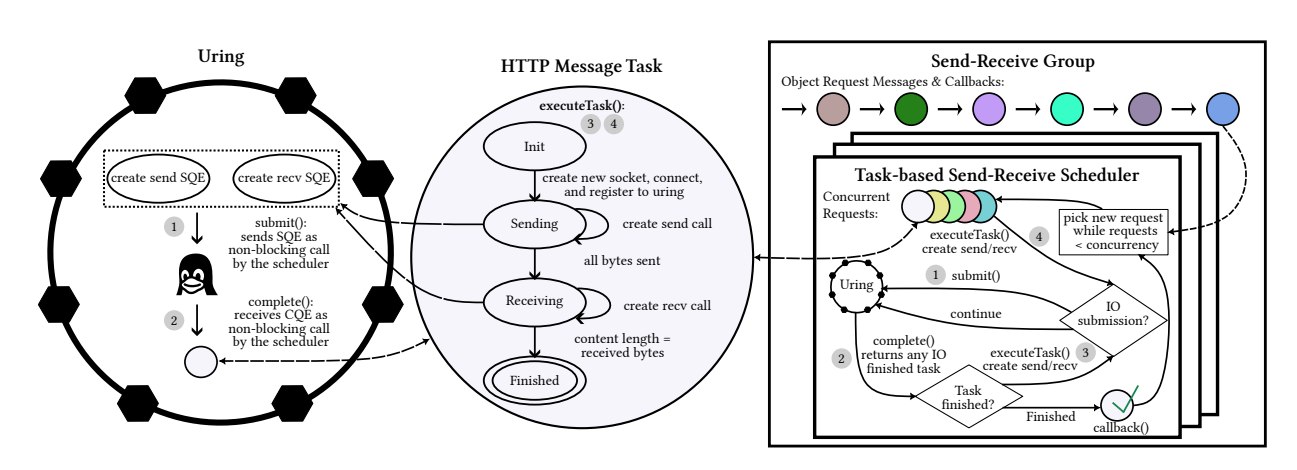 AnyBlob uses state-machine based message tasks that are asynchronously processed with the help of io_uring.
AnyBlob uses state-machine based message tasks that are asynchronously processed with the help of io_uring.
io_uring:(自Linux内核5.1起可用)为存储和网络任务提供通用的内核接口,它允许用户提交一个或者多个I/O请求,它们被异步处理而不会阻塞调用进程。它建立在两个无锁环形缓冲区(提交队列和完成队列)上,这两个缓冲区在用户空间和内核空间之间共享。io_uring 对于存储应用程序非常有效,但对于网络任务的研究较少。需要深入研究。
基于状态机的消息:每个请求会定义一个状态机,在状态机中实现云对象存储HTTP请求的不同阶段。状态机使得单个线程能够异步和多路复用消息。
异步系统调用:得益于io_uring,消息任务中对send和recv的系统调用异步处理。
基于任务的发送-接受调度器:利用基于io_uring的套接字和消息任务,我们开发了一个基于任务的发送接收调度器。该任务调度器使用一个线程,持续执行作为事件循环的步骤。
发送接收组。尽管单个基于任务的发送接收调度器具有高吞吐量(Gbit/s级),但这对于网络优化实例来说并不足够。因此,需要同时运行多个调度器。为了简化使用,采用无锁的发送接收任务组来管理多个发送接收调度器的请求。
身份验证和安全
透明认证:AnyBlob 实现了从多个云存储提供商上传和下载对象的操作。我们使用OpenSSL库实现了自定义的签名过程,以尽量减少核心数的情况下保持高吞吐量。
支持静态加密:AnyBlob 通过提供易于使用的、就地的、快速的 AES 加密和解密功能,支持用户应用程序使用静态加密。此外,AnyBlob 还允许请求使用 HTTPS(虽然大部分场景中并不需要)。
域名解析策略
解析域名带来相当大的延迟开销,AnyBlob做了如下优化:
- 缓存多个Endpoints的IP,避免额外的解析开销;
- 基于吞吐量的解析器,统计信息以确定端点运行状态,并用作调度的参考信息;
- 基于 MTU:不同 S3 节点具有不同的最大传输单元(MTU)。其中,一些 S3 节点支持使用最大 9001 字节的巨型帧(Jumbo frames),这可以显著降低 CPU 开销,因为每个数据包内核的 CPU 开销可以通过更大的数据包分摊;
- MTU 发现策略:通过对目标节点 IP 进行 ping,并设置 Payload 数据大于 1500 字节且 DNF(do not fragment, 不分段),以确定是否支持更大的 MTU。
性能评估
使用了AnyBlob,以及不同的S3 API实现,一个是官方的AWS C++ SDK,使用curl实现;另一个是S3Crt,使用AnyBlob的设计。
成本-吞吐量Pareto解(即多目标优化,在抠图算法中计算像素点距离和色相的偏移时也会应用此算法)显示,AnyBlob实现始终优于AWS C++ SDK。
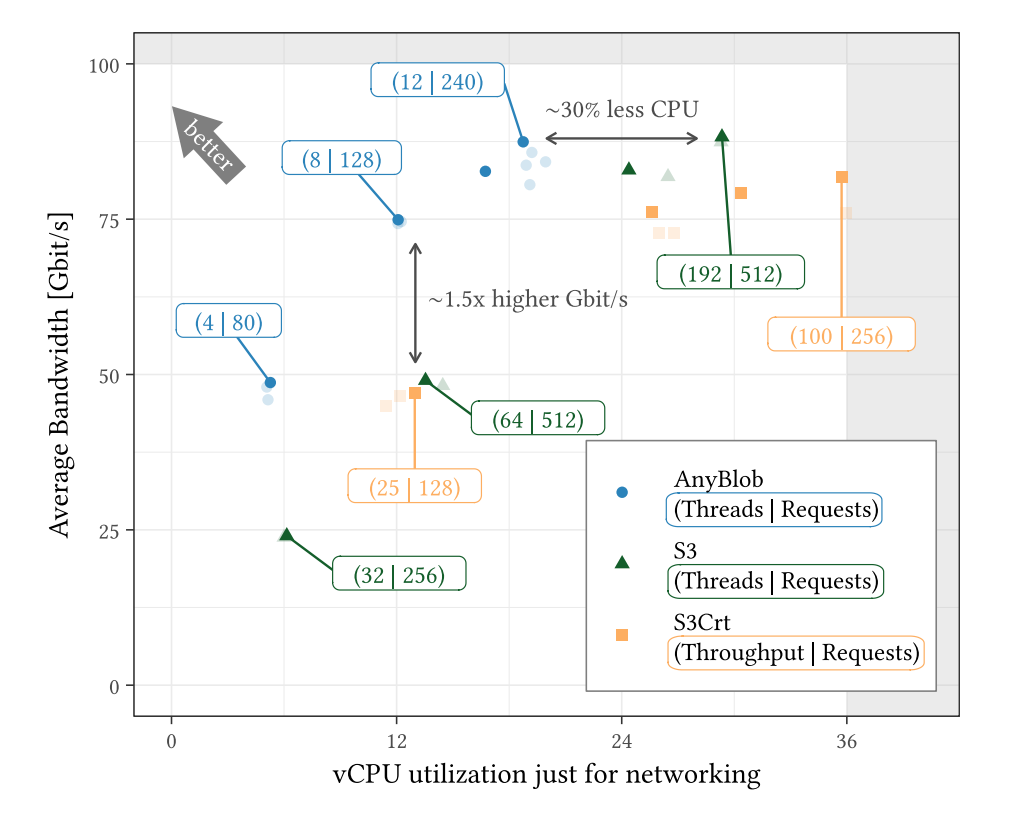 Throughput and CPU usage Pareto curves for AnyBlob, S3, and S3Crt (AWS, eu-central-1, c5n.18xlarge)
Throughput and CPU usage Pareto curves for AnyBlob, S3, and S3Crt (AWS, eu-central-1, c5n.18xlarge)
集成云存储
在这一部分,作者介绍了他们是如何集成云存储的。
一种简单的方式是每个工作线程只调度一个请求,单线程大部分时间会被阻塞于等待网络I/O。更常见的做法是采用异步I/O,但仍然面对线程数量过多的局面。
查询引擎需要平衡查询处理和下载。作者提出了一个调度组件,以平衡对象存储检索和查询处理,从而能够有效调度线程,优化查询性能和CPU使用。借助此调度器,作者开发了一种基于成本效益的列式存储格式的高效表扫描操作符(SCAN算子实现)。
数据库引擎设计
整体设计围绕表扫描算子展开。作者的DBMS Umbra使用一组工作线程来并行处理查询。其设计中,工作线程负责:
- 常规查询任务;
- 准备新的对象存储请求;
- 作为网络线程。
对象调度器根据网络带宽的饱和度和查询处理进度动态决定每个工作线程的任务。
大部分DBMS都采用任务调度的方式执行查询,异步检索机制只需要在查询运行时切换工作线程的任务机制。
列存格式:原始数据以列优先的关系格式组织,并以不可变的列块分块存储。块的元数据(如列类型和偏移量)存储在块头中。数据库的模式信息也存储在云存储中,这需要在启动时进行检索。
表元数据检索:接下来描述表扫描算子执行期间信息的流动,如下图所示。在步骤1和2中,扫描算子首先请求表的元数据,即块列表。随后,所有相关的块元数据会被下载,这作为开始SCAN算子数据检索的前提条件。
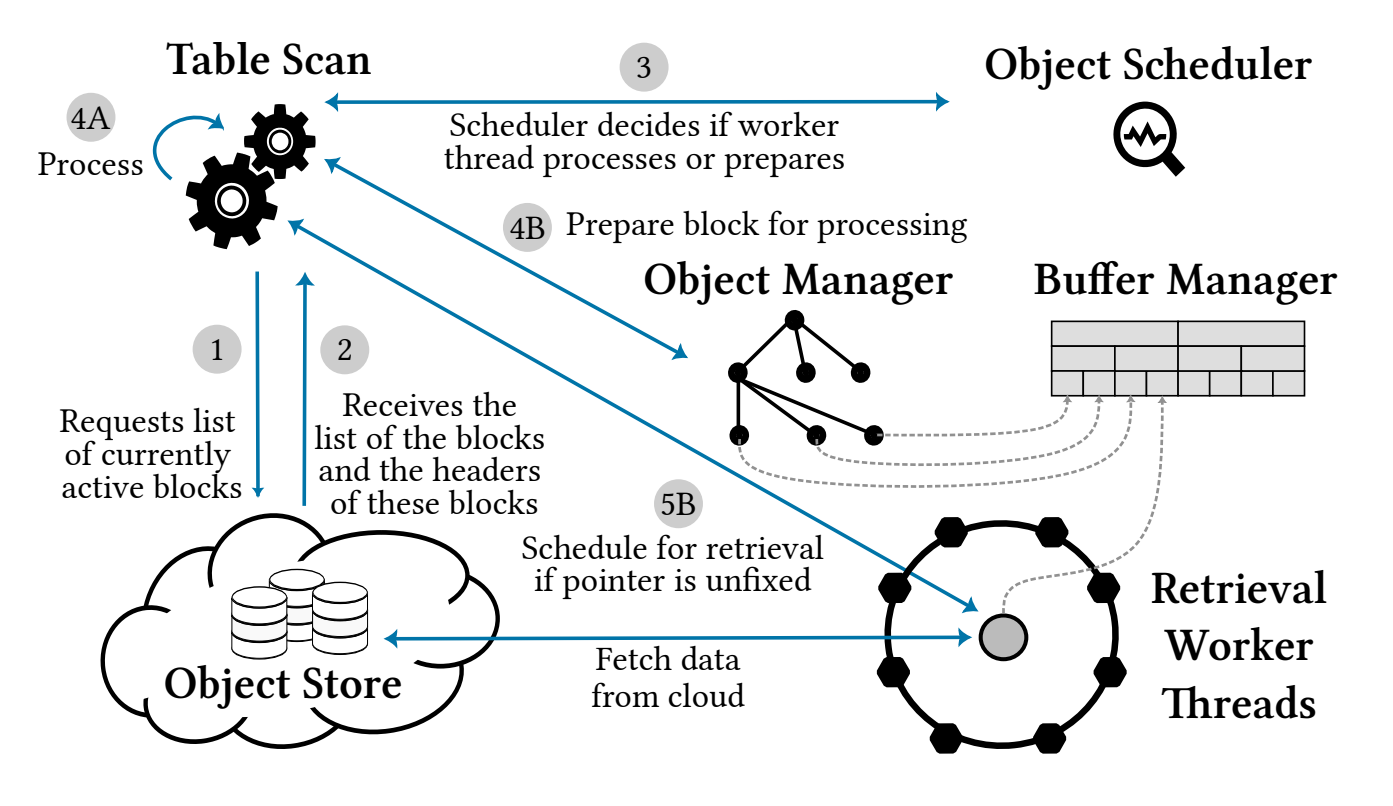 DBMS design overview for efficient analytics with the flow of information between different components
DBMS design overview for efficient analytics with the flow of information between different components
工作线程调度:在初始化表扫描之后,我们为这个操作分配了多个工作线程。由于将工作线程划分为检索线程和处理线程比较困难,并且在查询期间需要进行调整,我们实现了一个对象调度器来解决这个问题。
步骤3表明,每个扫描线程会向调度器询问应执行的任务。如果已经检索到足够的数据,工作线程会继续处理数据,如步骤4A所示。否则,我们会将线程分配为准备块检索的工作。
下载准备: 步骤4B中会创建新的请求,使得检索线程不间断地执行事件循环,由对象管理器保存元数据,以及创建请求检索。步骤5B中,检索线程提取数据。
Scan算子
Umbra的任务由称为“morsels”的小数据块组成。工作线程被分配到任务,并处理morsels,直到任务完成或线程被分配到其他任务。
Umbra初始化表扫描算子后,工作线程开始调用pickMorsel方法。该函数将任务数据的块分配给工作线程。每次完成后都会重复分配。我们的方法唯一的区别在于,工作线程不仅需要处理数据,还需要准备新的块或从存储服务器检索块。
工作线程任务:线程分配处理数据时将在pickMorsel函数执行时从当前活动块中挑选一个morsel(小块)。其他任务(准备和检索)不会从morsel中选择块进行扫描。相反,这些任务将启动准备或检索块所需的例程。不论任务内容为何,所有工作线程在完成当前任务后都会返回pickMorsel获取新任务。
下图的示例中展示完整的表扫描算子操作,8个线程中,4个执行数据处理,3个执行数据检索,1个用于准备新块。即包含三种任务:
- 处理任务;
- 准备任务;
- 检索任务。
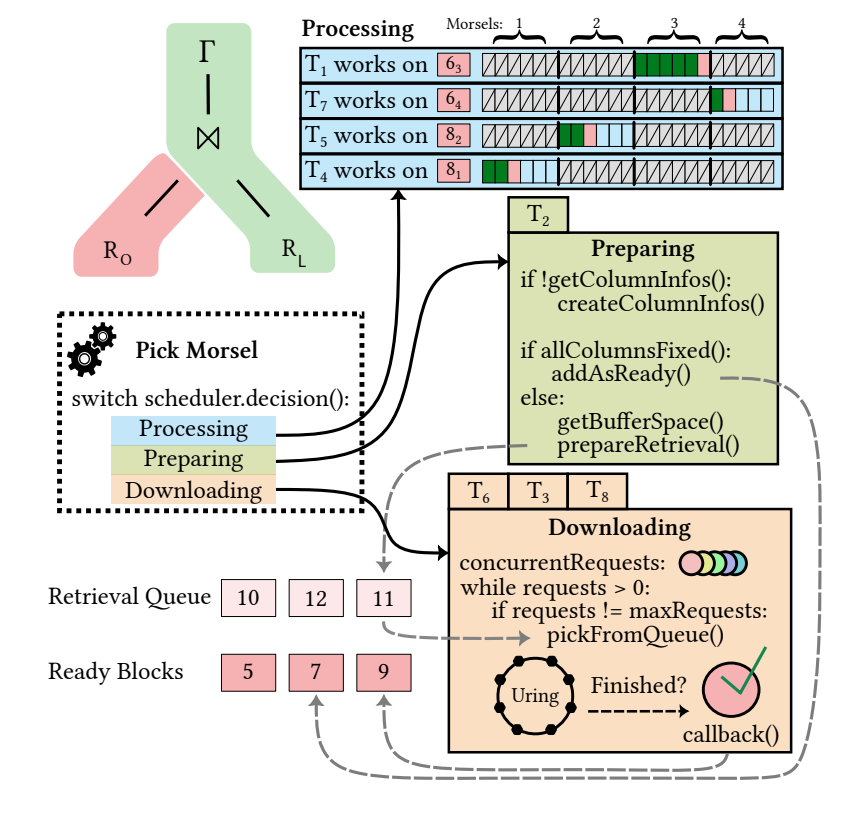 Table scan example with 8 threads
Table scan example with 8 threads
对象调度器
对象调度器的主要目标是平衡处理和检索对象存储性能。它将不同的任务分配给可用的工作线程,以实现这一平衡。如果检索性能低于扫描性能,它会增加检索和准备线程的数量。相反,减少检索线程数量会提高处理吞吐量。同时对象调度器也会考虑网络带宽的限制。
决策过程需要在检索和处理期间的性能统计数据。每个处理线程都会记录执行时间和已处理的数据量。聚合后的数据使我们能够计算每个线程的平均处理吞吐量。对于网络吞吐量,我们聚合当前时间段内的总体检索字节数。
[上文](#云对象存储特性)分析了达到目标吞吐量所需的并发请求数量以及相应的AnyBlob检索器数量。对象调度器根据未完成的检索请求(即正在传输对象存储数据)来估计网络带宽使用,并调度匹配数量的准备任务。
调度器计算处理与检索的全局比率,以平衡检索和处理性能。该比率用于调整检索线程数量和未完成带宽。计算方式参考算法1:
 Algorithm 1
Algorithm 1
超额准备:因为不希望处理线程阻塞等待数据,所以未完成带宽需要大于需要的带宽,最多为2倍。
AnyBlob使用了无锁原子值的统计数据和全局计数器,提供了快速的对象调度器决策。
关系&存储格式
- 列存;
- 为了实现成本效益的下载,每个块的列块应具有期望大小为16 MiB;
- 零拷贝,请求的数据块和缓存池的数据块大小一致;
- 透明分页,检索前会检查缓冲区数据块是否可用;
- 元数据结构,类似于Doris segment文件中的索引部分,不同的分析引擎有不同的设计,头部对象数少于数据块对象的数量;
- 扫描优化,通过MAX/MIN等索引结构优化查询;
加密&压缩
压缩: 在整数列上使用了位压缩,其他列上使用了LZ4;
加密: 静态加密不仅确保传输中的数据安全,还使数据在存储时对第三方不可访问。在上传列之前,我们使用AnyBlob对块中的各个列进行加密,使用AES加密会带来轻微的性能损耗。
实验评估
实验环境在单区域,72vCPUs/36cores、192GiB内存、100Gbit/s的实例上进行。
下载性能
作者将查询分为了两类,检索密集型(retrieval-heavy)和计算密集型,前者需要从对象存储读取更多的数据,后者需要更多的计算。与数据In-Memory的场景对比:
- 检索密集型:特点是 In-Memory 和 Remote 之间的性能差异是一个常数倍数;
- 计算密集型:特点是 In-Memory 和 Remote 之间的性能差异非常小。
不同存储的对比
AnyBlob > S3 Async > S3 > EBS.
扩展性
- 检索密集型的瓶颈出现在网络带宽;
- 计算密集型的性能随着核心增加而提升,吞吐量几乎与内存版本相同。
端到端压缩和加密
对比Snowflake,压缩比高了检索性能,但加密略损失了检索性能。
Ps. 貌似不大严谨,Snowflake对照组的信息不足。
读后收获
分析型的业务关键还是需要考虑吞吐量🤔。
另外,文中没有提到,其实S3支持分段上传和对象的部分下载。分析型的业务需要比普通的对象文件访问更加小粒度,高并发和高吞吐量的访问,因此才需要进一步的优化和调整。文中提到查询请求的最佳大小是8MB-16MB,即按照此大小来进行分片即可。