虚拟内存及malloc原理
Linux 内存模型以及编译链接原理.
笔记整理来源于 CSAPP 第九章 “Virtual Memory”。主要内容包括页表,硬件地址翻译,内存映射,动态分配。
虚存是对主存的抽象,主要作用有:
- 将 main memory 用作 disk 的 cache,只将 active 的部分放在 main memory,在需要时在 disk 和 memory 之间传递数据;
- 通过给应用程序提供统一的地址空间,简化内存管理;
- 通过给不同进程提供独立的地址空间,防止一个进程的数据被其他进程破坏(隔离性);
物理寻址和虚拟寻址
主存可以看作是由M个连续的字节大小的单元组成的连续数组(ps.这里还没有分成页)。物理寻址就是CPU通过访问目标主存数据在主存上的字节序号(即:物理地址)。现代操作系统通过访问虚拟地址,虚拟地址则需要通过地址翻译将地址转化为物理地址。
地址翻译由CPU上的内存管理单元(memory management unit)负责,简写为MMU。
地址空间
(线性)地址空间是连续的非负整数构成的集合,一个系统有一个物理地址空间[0,M−1],还有若干个虚拟地址空间 [0,N−1]。
虚拟地址空间总是2的幂,因此 N=2^n,称作n-bit地址空间,一般是 32-bit 或者 64-bit。
同一份数据可以在不同的地址空间有不同的地址,是虚存的一个基本思想。
虚拟内存的作用
此处对应本文开头的几个主要作用。
作为缓存的工具
页
虚拟内存和物理内存都会分割成固定大小的块,分别称为虚拟页,物理页/页帧。
任意时刻,虚拟内存上的页分为三个不相交的子集:
- 未分配的;
- 当前已经缓存在物理内存中的已分配页面;
- 当前未缓存在物理内存中的已分配页。
页表
物理内存上存放着一种叫页表的数据结构,页表将虚拟页映射到物理页上。地址翻译需要MMU,操作系统和页表共同完成。
页表是一个页表条目(Page Table Entry)数组,虚拟地址空间中每个页在页表中一个固定偏移量处都有一个条目。每个条目包括一个有效位(valid bit)和一个n位地址字段。表示虚拟页表的情况包括:
- 有效位为1,地址直段表示了该虚拟页在物理内存中的地址,已缓存;
- 有效位为0,地址字段为空,该虚拟页未分配;
- 有效位为0,地址字段表示虚拟页在磁盘上的位置,该虚拟页未缓存;
虚拟地址空间往往很大,可以将页表压缩为多级页表。
缺页
MMU访问虚拟地址的PTE,若虚拟页没有缓存在物理内存上,则发生缺页。
缺页发生后,操作系统会在物理内存上选择一个页面进行淘汰,必要时将其内容写到磁盘上,并将该页面的页表项标记为未缓存;将请求页面有磁盘加载到主存中,并标记为已缓存。
虚存的缺页中断是非常昂贵的,因为会触发磁盘的随机读写,但由于程序访问内存的局部性,一般来说缺页很少触发,效率就不会太差。工作集过大超过物理内存,从而不断触发缺页的情况称作抖动(thrashing),会大大影响程序的效率。
作为内存管理的工具
操作系统为每个进程提供了一个独立的页表,也就是独立的虚拟地址空间。虚拟内存为内存管理提供了如下便利:
- 简化链接;使得链接时无需考虑具体的物理地址,不同程序可以使用同样的虚拟地址分配方案。
- 简化加载;加载程序时只需将可执行文件的段落映射到虚存中,不用拷贝数据,等访问到某个页面时出发缺页中断时再进行加载;
- 简化共享;操作系统可以将进程私有的数据映射到不同的物理页面,而将共享的数据映射到相同的物理页面(动态链接库的原理);
- 简化内存分配;请求虚拟页面时,实际分配页面由操作系统托管。
内存保护的工具
- 虚存可以轻松地给不同的进程提供不同的私有内存空间,从而隔离不同进程;
- 通过给 PTE 添加许可位
SUP、READ、WRITE,可以控制该页是否只能由内核进程访问,以及其读写权限。
如果访问一个页面的时候权限出错,Linux shell将其视为段错误(segment fault)。
Linux 虚拟内存系统
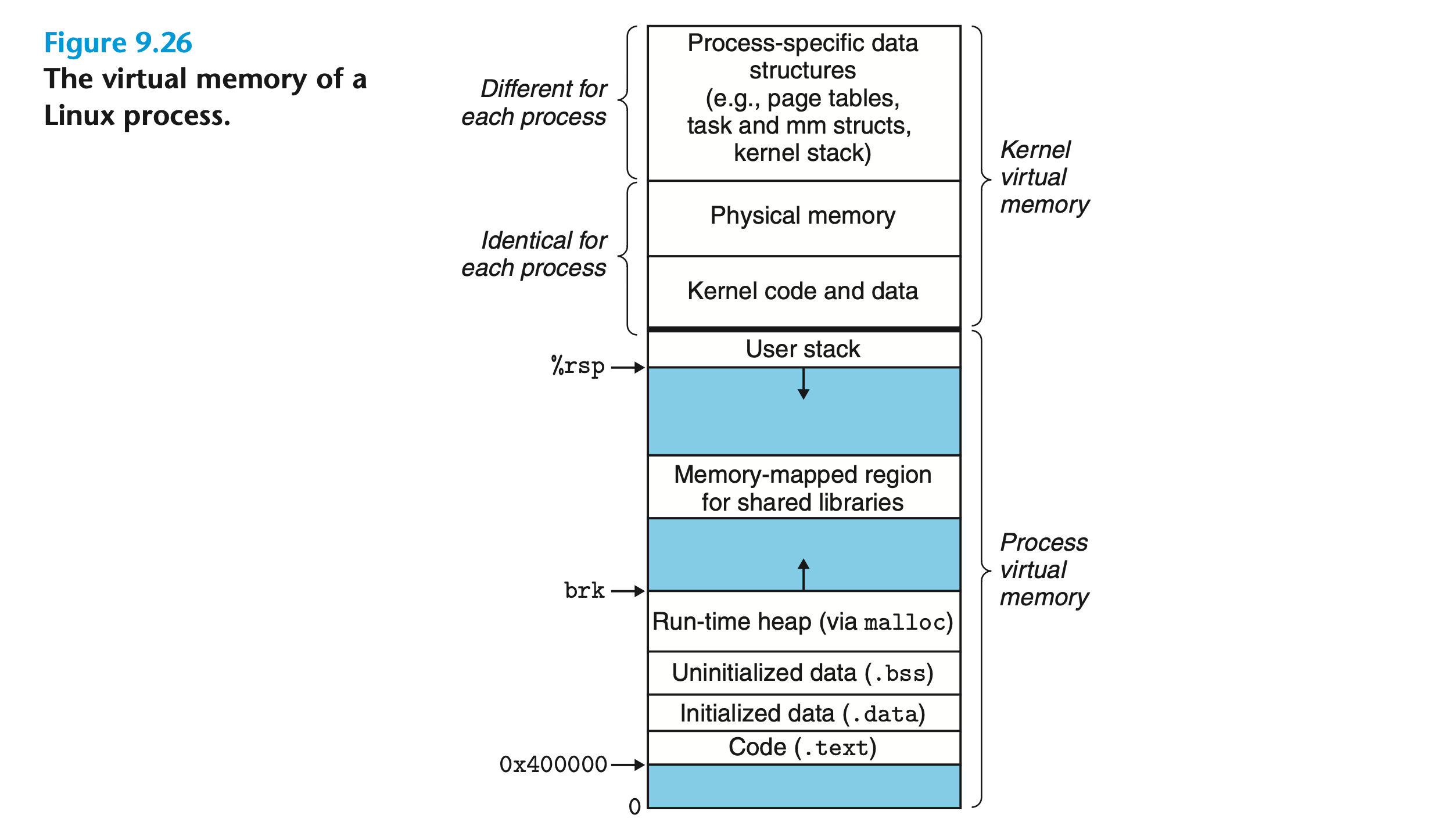
图中从虚拟地址0开始,每个区域(除了空白处)分别为:
- 代码段;
- 已初始化数据;
- 未初始化数据;
- 运行时堆(通过malloc分配的),向高位地址增长;
- 共享库的内存映射区域;
- 用户栈,向低位地址增长;
- 内核虚拟空间;
- 内核代码和数据;
- 物理内存;
- 与进程相关的数据结构(比如页表,task和mm结构,内核栈等)。
Linux 将虚拟内存划分为多个区域或段(Area 或 Segment),每个区域都是一些已分配且在某些方面相关的连续页面。例如,代码段、数据段、堆、共享库段和用户栈分别是不同的区域。每个已分配的页面都属于某个区域,因此不属于任何区域的页面不存在也无法被进程引用。区域概念的引入使得 Linux 允许虚拟地址空间存在间隙。
内存映射
Linux通过将一个虚拟内存区域跟磁盘上的一个对象关联起来,以初始化这个虚拟内存区域的内容,该过程称为内存映射 (memory mapping)。操作系统会等到直接访问某个具体页面再将指定的页面放到物理内存中。
内存映射有两种:
- 映射共享对象;修改对其他进程可见;
- 映射私有对象;修改对其他进程不可见,也不会同步到磁盘上,而且是写时复制的。
fork原理
内核调用fork时,为新进程分配一个新的PID,必要的数据结构,然后创建了当前进程的mm_struct、区域结构和页表副本。将两个进程的页面都标记为只读,且在之后写入的时候触发写时复制。
execve
execve执行的原理为:
- 删除当前进程的用户区域;
- 映射私有区域,包括代码,数据,bss和栈区等;
- 如果有 link 到共享库,会进行动态链接,将共享库映射到虚拟地址空间中的共享区域;
- 设置程序计数器(PC), 使其指向代码区域的入口点。
mmap
mmap函数用于在linux中申请一段起始地址为addr,长度为length的内存虚拟区域,并将文件fd中从 offset 开始的length个字节映射到这段内存上。
1
void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset)
在mmap的函数声明中:
- addr: area 的起始地址,仅作提示作用,一般 NULL 就行;
- length: area 的长度;
- prot: PROT_EXEC、PROT_READ、PROT_WRITE、PROT_NONE;
- flags: 有很多,常用的有 MAP_SHARED、MAP_PRIVATE、MAP_ANONYMOUS;
- fd: map 到的 file descriptor;
- offset: map 到的文件内容的 offset,必须是 page size 的倍数;
对应的,munmap用于删除一段虚拟内存的区域:
1
int munmap(void *addr, size_t length)
动态内存分配
虽然可以用mmap和munmap来创建和删除虚拟内存的区域,但这需要复杂的地址管理,因此动态内存分配器被用以负责申请和释放内存块。现有的分配器有两种风格:
- 显式分配器:比如C语言中的malloc/free,C++中的new/delete,要求显式地释放任何已分配的块;
- 隐式分配器:由分配器检测一个已分配块何时不再被程序所使用,并将不再使用的内存块释放。这种分配器称为垃圾收集器,这种自动释放内存块的机制称为垃圾回收。Lisp、Java等语言使用的就是这种策略。
malloc和free
可以通过malloc/calloc/realloc分配块并获得指向该内存块指针,free函数则可以根据此指针释放该内存块。
申请的内存块有内存对齐要求,申请的数据块需要是一个固定大小(比如两个字节)的倍数。
分配器
分配器需要做到:
- 能够处理以任意顺序发送的 allocate 和 free 请求(不能对顺序做任何假定);
- 立即对请求做出响应(不能离线);
- 只使用 heap 存储数据(不能将数据存储在虚存的其他位置);
- 满足对齐要求(能够存储任何类型的数据);
- 不能修改或移动已分配的块(可以修改 free block 或者 heap 中不是 block 的区域);
简单地遍历是一种方案,但要实现高性能,有两个性能目标:
- 最大化吞吐量;需要提高请求的处理速度;
- 最大化内存利用率;
造成堆的利用率很低的主要原因是内存碎片,包括:
- 内部碎片,即申请的内存块大小不满足对齐要求,分配器需要增加块大小满足对齐约束;
- 外部碎片,即空闲的内存不连续,合计起来可以满足分配请求,但是却没有一个单独的空闲块可以满足请求。
隐式空闲链表
隐式分配器将块的信息嵌入块本身,不论是已分配块还是空闲块,内存块被划分为:
- 头部,包括3位的其他信息(区分是否空闲等),29位的块大小信息;
- 有效载荷,
- 填充,可能用于应对外部碎片,或者用于对齐等。
头部包含大小字段,可以找到下一个块的其实地址。因此空闲块隐含地连接起来,这种结构也称为隐式空闲链表。这种结构还需要一个特殊标记的结束块。
隐式空闲链表优点是简单,显著缺点是任何操作的开销,与已分配块和空闲块的数量成线性关系。
放置策略
分配块时需要找到一个足够大的空闲块,分配器进行这样的搜索的方式称作放置策略(placement policy):
- 首次适配(first fit):从头开始找,直到找到足够大的空闲块;
- 下一次适配(next fit):从上次搜索结束的地方开始找,直到找到足够大的空闲块;
- 最佳适配(best fit):遍历所有空闲块,使用足够大的空闲块中最小的;
其中,内存利用率ff < nf < bf
分割空闲块
如果分配时空闲块的剩余空间比需要的空间大,且大的超过一个块的最小大小(2个byte,如果不超过可以作为内部碎片),就可以将这个空闲块分为两半,一半用作分配块,另一半为空闲块。
获取额外的堆空间
如果已有的堆空间没有空闲块可以满足分配,需要使用sbrk函数,向内核请求额外的堆内存。
brk指针指向堆在虚拟内存中的边界,sbrk通过修改该指针指向的位置来改变堆的大小。
合并空闲块
如果很多空闲块相邻地放在一起,可能会造成假碎片(false fragmentation),即合并后能放下但每个单独无法放下,所以需要对相邻的空闲块进行合并 (coalesce)。
合并根据合并时机分类,有两种策略:
- 立即合并,每次释放块时,立即合并相邻的空闲块,实现简单,但可能造成反复的合并和分割,带来性能浪费;
- 推迟合并,等到某个时候再合并,例如在未能找到足够大的空闲块时。
头部记录的块大小可以让我们知道下一个块的位置,但是却没办法知道上一个块的起始位置。因此合并时需要知道上一个空闲块的信息,这可以通过在空闲块尾部添加一个与头部内容相同的脚部来实现,这被称作使用边界标记(boundary tags)。由于只有空闲块需要脚部,可以省去分配块的脚部,而在头部的分配位中记录上一块是否分配,来节省空间。
显式空闲链表
可以在空闲块中存储指向前驱后继的指针来维护一个空闲块的链表,称作显式空闲链表。
这个链表可以是 LIFO(先进后出)的或者按地址顺序的。LIFO 的链表可以在常数时间内完成 free 操作,而按地址顺序的链表需要使用线性时间来找到一个空闲块在 list 中的位置,但内存利用率更高。
由于需要足够大的空间来存储前驱后继的指针,显式空闲链表的块最小要求更大,可能会出现更严重的内部碎片导致内存利用率下降。
分离的空闲链表
可以将空闲块按照大小分类,例如按 2 的次幂分类,每一类维护一个链表。具体实现方式有很多,例如简单分离存储和分离适配。
简单分离存储
每个大小类的空闲链表包含大小相等的块,如果一类空闲块用光了就申请新的堆空间,释放时直接放回相应的链表,不合并也不分割。
这样的话,头部和脚部都不需要了,只需在空闲块里存放一个后继指针即可,但内部碎片和外部碎片都很严重。
分离适配
为了分配一个块,对相应的类别进行首次适配,找不到就继续找下一类。这种效果近似最优适配。释放块式执行合并,并将空闲块放置到对应大小类的空闲链表中。
C标准库的GNU malloc使用的就是分离适配的策略。
垃圾回收
可以通过 block 之间以及 stack、register、global 变量对 block 的引用关系找到不可达的 block 而进行 garbage collection。
在 C 中,由于没有类型信息,可能会将非指针类型的数据视作对 block 的引用,导致不可达的 block 被视作可达,所以 C 语言的 garbage collection 只能是 conservative 的。