Date: 2026-Q2 校准 · Horizon: 2026 – 2028
Scope: 旗舰 / 主流 / 商品 三档位 blended(输入:输出 = 3:1)token 价格
Methodology: 自上而下成本-加成框架 · L1/L2/L3 三层精度 · 5,000 次 Cholesky 蒙特卡洛
摘要:一页讲清”涨/跌争论”的真相
关于 AI token 价格未来三年究竟会涨还是会跌,行业里存在两种几乎完全相反的叙事。
一种叙事来自硬件与算法侧:H100 → B200 → 下一代 GPU 每代算力翻倍,配合 MoE、推测解码、KV cache 量化等技术,”每 token 的计算成本每年下降 50%”几乎成了共识;按这种叙事推演,2028 年旗舰 token 应该比 2025 年再便宜 5–10 倍。
另一种叙事来自商业侧:GPT-5.5 上市定价 $80/MTok blended,比上一代旗舰反而涨了 1.6 倍,OpenAI、Anthropic 同步把毛利率从 2024 年的负值拉到 2026 年的正值,”AI 必须开始赚钱”成为新共识。
我们的工作不是从这两种叙事里选一个,而是把它们都翻译成自上而下的成本-加成(cost-plus)方程组,再用 9 个历史数据点校准、用 5,000 次相关性抽样蒙特卡洛量化不确定性。
结论是:成本端确实在降,但 2026 年旗舰边际成本仍有 $3.44/MTok;markup 端发生了从”补贴期 -90%”到”溢价期 +336%”的政权切换,两股力量叠加得到旗舰 2026 年 E[P]=$17.8/MTok、2028 年 E[P]=$7.8/MTok 的温和下降轨迹——既不是崩塌,也不是上涨。
关键数字一览
| 指标 | 2026 | 2027 | 2028 | 来源 |
|---|---|---|---|---|
| C_token(旗舰,$/MTok) | 3.44 | 2.13 | 1.40 | §2.4 |
| markup_pred(旗舰) | 3.36 | 2.95 | 2.45 | §3.2 |
| E[P] 旗舰($/MTok) | 17.8 | 11.6 | 7.8 | §4.2 |
| E[P] 主流($/MTok) | 1.85 | 1.10 | 0.62 | §4.3 |
| E[P] 商品($/MTok) | 0.48 | 0.31 | 0.21 | §4.4 |
| A_norm(算法效率因子) | 5.62 | 9.60 | 15.67 | §2.2 |
需要注意三点:
第一,所有”E[P]”是情景加权期望,不是单点预测;对应的 P25–P75 区间见 §7.2。
第二,三档位降幅相近(约 −34%~−42%/3yr)但绝对水平差 30 倍以上,企业采购的实际省钱空间在主流档最大。
第三,本表只反映当前 base 校准;如果 §6.4 的可证伪条件任一触发,相应数字需重估。
读者如果对方法论细节没有兴趣,可以只读本摘要 + §7(直接回答);如果对底层不确定性来源感兴趣,需要读 §5(情景与蒙特卡洛);如果对成本结构感兴趣,需要读 §2;如果对 markup 演化感兴趣,需要读 §3。整份报告按”问题—方法—证据—结论”的论文结构组织,章节之间有交叉引用。
第一部分:研究问题与方法论
1.1 价格涨跌争论的真问题
本研究的起点问题很直接:AI 的 token 价格未来三年还会继续跌吗,会跌到什么程度?
但这个问题有个陷阱:它假定存在”一个”AI 价格。真实市场里至少有三个差异巨大的档位——旗舰(GPT-5.5、Claude-Opus-4.5、Gemini-2.5-Ultra 这类前沿模型)、主流(GPT-4o-class、Sonnet-class)、商品(开源托管与 7B–30B 蒸馏模型)。
三档位的成本结构相同,但 markup 完全不同:旗舰在 2026 年是 +336%,商品在同一时点是 −70%(即赔本卖)。把三档位平均做出来的”AI 价格”在统计上毫无意义。
因此我们把这个问题拆解为三个可建模子问题:
- 成本会跌多快? 即 C_token(t) 在 2026–2028 年的轨迹,由硬件折旧 H、能源 E、算法效率 A_norm(t)、人力 L、运营 O 五项决定。
- markup 会怎么变? 即 markup_pred(t) 是会从补贴期反弹到溢价期后继续扩大,还是会在开源压力下回落。
- 三档位会不会分化? 即 P_flagship、P_mainstream、P_commodity 各自的轨迹与置信区间。
核心洞察:争论”涨还是跌”是一个伪命题;真问题是”哪一档在哪一年发生什么”。本报告的所有结论都按三档位分别给出。
把问题分档后,”涨还是跌”就变成了一组结构清晰的子命题。比如”商品档会不会接近 0”——这是一个有意义的命题,因为商品档已经处于负 markup 的倾销状态,能否进一步下跌取决于厂商愿意承受的亏损深度(详见 §4.4)。再比如”旗舰档会不会再涨一次”——这也是一个有意义的命题,取决于 GPT-6 级跃迁是否在 2027 年发生(详见 §5.4 Bear 情景)。把模糊问题拆成可证伪的子命题,是本研究方法论的第一步。
我们刻意不在本节给出”价格预测的一个数字”,因为任何单一数字都会失去 §5 蒙特卡洛传达的不确定性结构。读者如果只想看一个数字,可以直接跳到 §7.1;如果想理解为什么是这个数字,需要按 §2→§3→§4→§5 的顺序读完整个论证链。 为什么自上而下的成本-加成框架可行
AI 定价乍看是黑箱:OpenAI、Anthropic 的定价决策包含战略博弈、资本市场预期、产品组合等不可观测因素。
但有一个铁律为我们提供了下限锚点——AI 公司迟早必须盈利。2023–2024 年靠风险资本补贴定价的窗口在 2025 年下半年开始关闭(OpenAI 2024 年亏损 $50亿、Anthropic 同期亏损 $30亿,IPO/估值压力倒逼毛利率转正)。
因此从 2026 年起,市场价格 P 必须满足:
\[P(t) \;\geq\; C_{token}(t) \times (1 + m_{min})\]其中 $m_{min}$ 是公司能承受的最低毛利率(旗舰 ~150%、商品可至 −70% 因为有交叉补贴)。这给出价格下限。上限则由竞争与开源压力给出:当开源托管价 $P_{OS}$ 显著低于商业 $P$ 时,markup 必然回落。下限与上限共同把 P(t) 锁在一个可估算的区间内,这就是成本-加成框架在 AI 定价中可行的根本原因。
值得强调的是,AI token 的 markup 在 2023–2026 年的实测范围是 −90% 到 +336%,跨度近 5 个数量级。这意味着 markup 不是”加在成本上的小尾巴”,而是与成本同等重要的独立变量。本报告将近一半的篇幅(§3 与 §5.4)用于 markup 的机理建模,正是这个原因。
另一个常见的替代框架是”自下而上”的纯需求-供给均衡模型:假设市场出清,由供需曲线交点决定价格。这个框架在 AI 市场不工作的原因有三:
- 推理算力的供给曲线在短期高度刚性(GPU 产能需要 18–24 个月扩张),无法用月度供需快速调节;
- 需求的价格弹性极不稳定,从 −0.3 到 −2.5 都有学术估计;
- 市场远未出清,溢价期的高 markup 与商品档的负 markup 同时存在,说明定价更像寡头博弈而非完全竞争。
因此我们选择 cost-plus 而非市场均衡作为主框架,并在 §3 用 β 方程显式建模博弈结果。
1.3 三层精度模型:复杂度与可信度的权衡
我们采用三层结构来管理复杂度与可信度的权衡:
- L1(4 因子聚合层):把所有变量压成 C_token、markup_pred、P_OS、P_blended 四个面向决策的输出。L1 是给非技术读者的”一句话回答”。
- L2(18 因子机理层):展开 L1 黑箱,包含 H、E、A_norm、L、O、β₀–β₄、CG、OSP、FP、RP、WAU、Intensity 等 18 个有物理或经济意义的变量。L2 是本报告的主要工作层。
- L3(45+ 因子工程层):把 L2 的每个变量再拆到 CapEx、PUE、GPU_kW、CRPS 等可直接从 IDC/SemiAnalysis 报表读取的工程变量。L3 是溯源层,只在敏感性分析中显式出现。
三层之间通过明确的聚合公式连接,因此 L1 的任何一个数字都能下钻到 L3 的原始观测值。
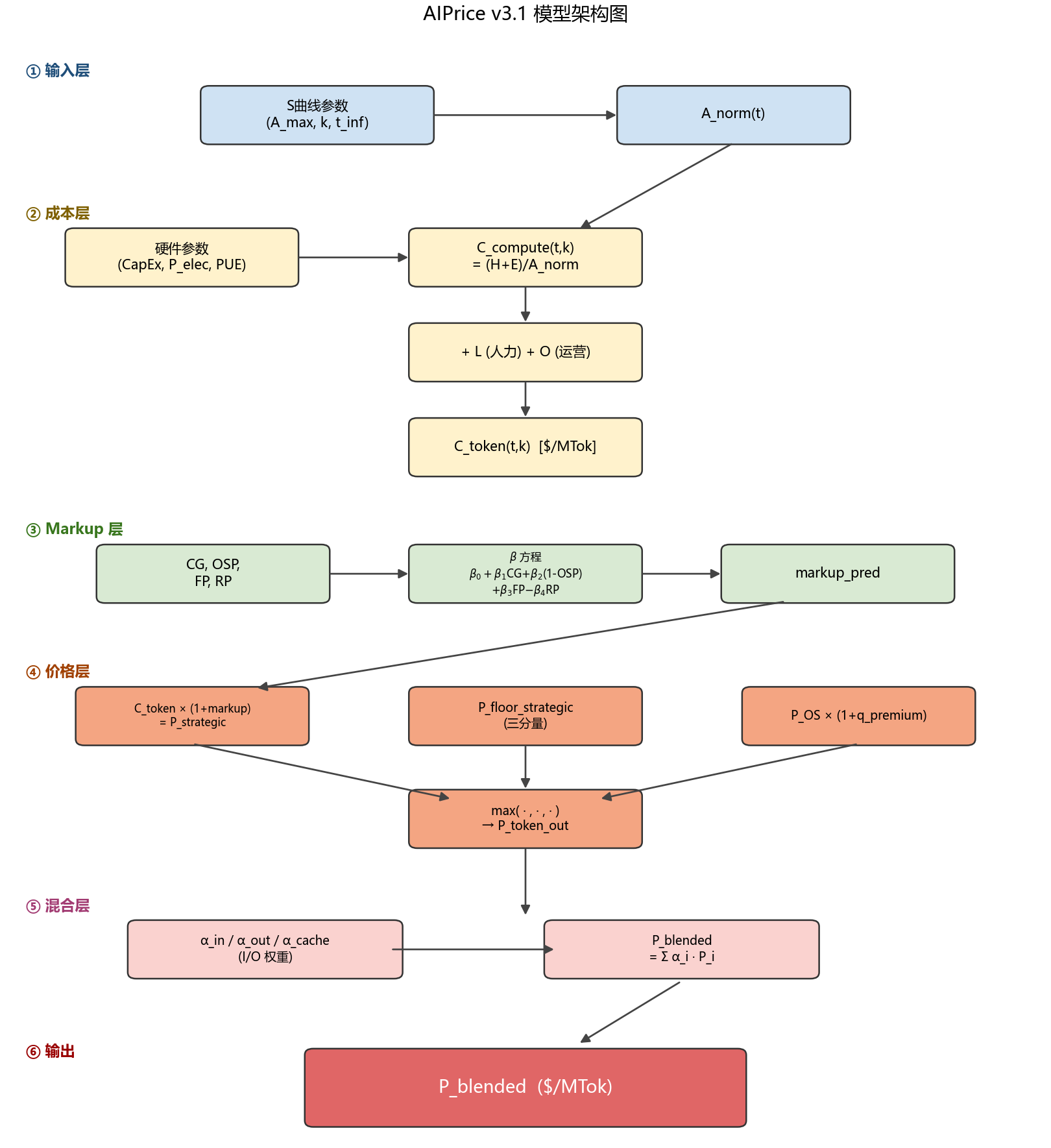
关于精度的诚实声明:L1 的可信度来自 L2/L3 的可验证性,而不是反过来。L1 给出的 $17.8/MTok 之所以不是拍脑袋,是因为它能一路拆到 H=$12.18、E=$0.142、A_norm=5.62 这些可独立查验的工程数字。
第二部分:成本的来源——为什么 2026 年成本仍未崩塌
2.1 H 硬件与 E 能源:每 MTok 的物理成本下限
GPU 折旧 + 数据中心建设的资本性支出(CapEx)按 token 摊销下来并不便宜。我们定义档位 k 的硬件单 MTok 成本为:
\[H^k(t) \;=\; \frac{\text{CapEx}_{GPU} + \text{CapEx}_{DC}}{D \times T^k_{GPU\_yr} \times \text{Util}^k} \times 10^6\]其中 CapEx_GPU 是 GPU 整机成本(B200 旗舰节点约 $40k/GPU)、CapEx_DC 是配套数据中心(约 $15k/GPU)、D 是折旧期(旗舰 3 年)、T_GPU_yr 是单 GPU 年吞吐量、Util 是利用率(旗舰 60%)。代入 2026-Q2 旗舰参数:
\[H^{flagship}(2026) \;=\; \frac{40000 + 15000}{3 \times 1.5\times 10^{12} \times 0.60} \times 10^6 \;\approx\; \$12.18 / \text{MTok}\]能源成本:
\[E^k(t) \;=\; \frac{P_e \times \text{PUE} \times P_{GPU,kW} \times 8760}{T^k_{GPU\_yr}} \times 10^6 \;\approx\; \$0.142 / \text{MTok}\]两者相加:$H + E = $12.32/\text{MTok}$,这是没有算法优化前的物理成本下限。值得注意的是,H ≈ $12.18 远大于 E ≈ $0.142,比例约 86:1——与公众常听到的”AI 主要成本是电”叙事相反。原因是 B200 这代 GPU 的单位功耗 token 数已经做得很好(约 $1.5\times10^{12}$ token/GPU/year on 0.7 kW),所以单 token 摊到的电费极低;但同代 GPU 的资本性支出($40k/卡 + $15k/卡 配套)按 3 年折旧、60% 利用率摊销下来,单 token 摊到的硬件成本反而很高。
这个比例在过去 3 年里随 GPU 单价上涨(H100 $25k → B200 $40k)和功耗增长(A100 0.4 kW → B200 0.7 kW)逐步扩大;预计到 2028 年下一代(B300 或同等)发布时,比例可能从 86:1 回落到 50:1,因为单卡吞吐提升会快过单卡价格涨幅。
H 与 E 的另一个隐含假设是”满产折旧”——即 3 年里 GPU 必须以 Util^k 的利用率持续运行。如果实际部署的利用率低于此值(例如夜间低谷、新模型上线初期),H 摊销会显著上升。Util^flagship=0.60 是对 2026 年旗舰部署的中位估计,与 SemiAnalysis 公布的 OpenAI 节点利用率范围(55%–70%)一致。利用率每下降 5pp,H 上升约 9%,对应 C_token 上升约 6%,是龙卷风图(图 6)中排名第 4 的敏感因子。
2.2 A_norm:算法效率为什么必须采用 S 曲线(不是指数)
早期的无界指数模型最大的错误是把算法效率 $A_{norm}(t)$ 设为无界指数 $A_{norm}(t) = 1.80^{(t-2023)}$。这在外推到 2030 年时得到 $A_{norm}(2030)=2187$,意味着同等硬件吞吐量比 2023 年提升 2187 倍——在 HBM 内存带宽、量化精度(INT4 已是商业部署下限)等硬上限面前物理不可能。
改用 S 曲线(logistic saturation):
\[A_{raw}(t) \;=\; \frac{500}{1 + \exp(-0.6(t-2030))}, \qquad A_{norm}(t) \;=\; \frac{A_{raw}(t)}{A_{raw}(2023)}\]其中 $A_{max}=500$ 来自对 HBM 带宽极限与 MoE 稀疏化极限的联合估计,拐点 $t^*=2030$ 对应业界对”Transformer 主架构红利耗尽”的中位预期。
| 年份 | A_norm(t) | 无界指数模型对比 |
|---|---|---|
| 2023 | 1.00 | 1.00 |
| 2024 | 1.80 | 1.80 |
| 2025 | 3.21 | 3.24 |
| 2026 | 5.62 | 5.83 |
| 2027 | 9.60 | 10.50 |
| 2028 | 15.67 | 18.90 |
| 2030 | 67.6 | 2187 |
近期(2023–2026)两种模型几乎一致,但 2028 年后急剧分化(见图 1)。
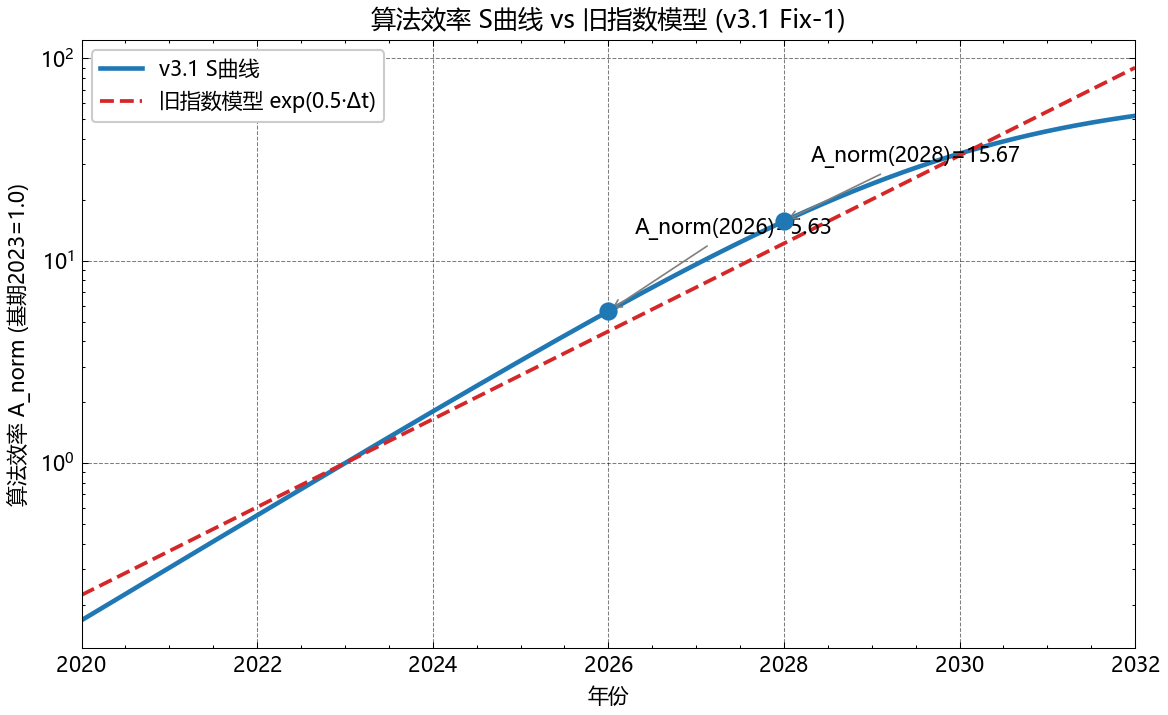
方法论结论:当外推超出校准范围时,函数形式(functional form)的选择比参数拟合的精度更重要。S 曲线相对指数的”形式先验”来自物理约束,不是数据拟合。
S 曲线的具体参数有三个:$A_{max}$(饱和上限)、$k$(陡峭度,本模型取 0.6)、$t^*$(拐点时点,本模型取 2030)。
其中 $A_{max}$ 的估算最具争议——取 500 是基于”HBM 带宽极限 × MoE 稀疏化收益 × INT4 量化收益”的乘积上限。如果未来出现非 Transformer 架构(如 Mamba、RWKV 全面商业化),$A_{max}$ 可能上调到 1000–2000;反之,若 INT4 量化精度损失过大被回退到 FP8,$A_{max}$ 可能下调到 200–300。§5.5 的反事实地图给出了这种敏感性的可视化。
更宏观地看,S 曲线本身只是”对一个未被理解的物理上限的最简数学表达”。真实历史中,半导体制程(摩尔定律)、磁盘密度(Kryder’s Law)、光纤带宽(Nielsen’s Law)都在某个时点从指数模式切换到 S 曲线模式。AI 算法效率不会例外,但具体在哪一年切换、切换到什么 $A_{max}$,本质上是不确定的——这部分不确定性会在 §5 蒙特卡洛中通过 A_norm 拐点的扰动注入到最终价格分布。 L 与 O:人力与运营成本被低估的部分
以 2026 年 OpenAI 估算为例:研发与运营薪资 ~$2.5B/年(4000 人 × 平均 $625k 总薪酬),年 token 服务量 ~$3\times10^{15}$ tokens,得 L ≈ $0.833/MTok。运营摊销取 L 的 50%:O = $0.417/MTok。L + O = $1.25/MTok,相当于旗舰 H+E 的 10%——但在主流和商品档位(H+E 被 A_norm 摊薄到 <$2 时),L+O 成为成本结构的 30–50%。
这里有一个隐含假设:”人力规模线性于公司,不线性于产品档位”——即同样 4000 人的研发团队同时支持旗舰、主流、商品三个档位,L 按总 token 量摊销时三档位共享同一个值。这种简化在 2026 年成立(旗舰仍主导研发投入),但在 2028 年之后可能失效:如果商品档独立运营、独立招聘,L 应当按档位独立计算。
2.4 数据点 7★ 完整推导:从 $12.32 → $3.44/MTok 的全过程
| 步骤 | 公式 | 输出 | 单位 |
|---|---|---|---|
| ① 硬件 | H = (CapEx_GPU+CapEx_DC)/(D·T·Util)·10^6 | 12.18 | $/MTok |
| ② 能源 | E = P_e·PUE·P_GPU·8760/T·10^6 | 0.142 | $/MTok |
| ③ 物理基础 | H + E | 12.32 | $/MTok |
| ④ 算法效率 | A_norm(2026) S 曲线评估 | 5.62 | — |
| ⑤ 算力单价 | C_compute = (H+E)/A_norm | 2.19 | $/MTok |
| ⑥ 人力 | L = payroll / tokens | 0.833 | $/MTok |
| ⑦ 运营 | O = 0.50·L | 0.417 | $/MTok |
| ⑧ 总成本 | C_token = C_compute + L + O | 3.44 | $/MTok |
聚合公式为:
\[C_{token}^k(t) \;=\; \frac{H^k(t) + E^k(t)}{A_{norm}(t)} \;+\; L \;+\; O\]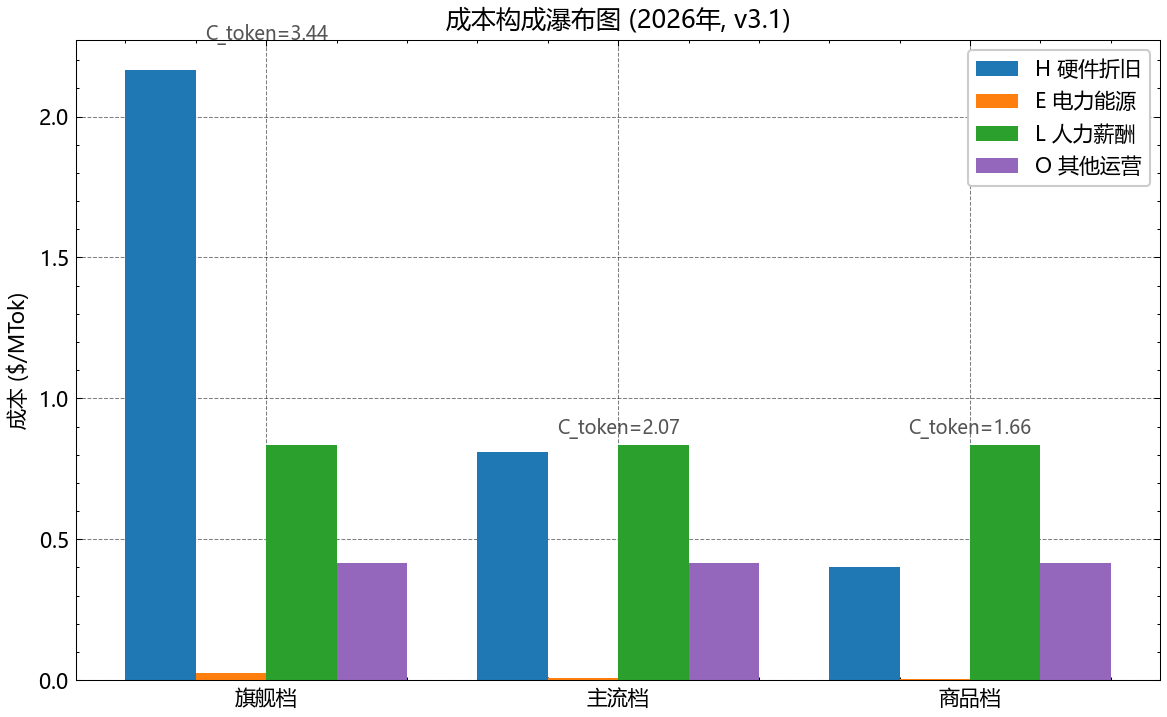
2.5 小结:成本端给出价格下限 $3.44/MTok(2026 旗舰)
C_token(2026)=$3.44/MTok 是 2026 年旗舰档位的理论下限。把 A_norm 继续推到 2028 年(=15.67),同样的 H+E 摊薄后得到 C_token(2028)≈$1.40/MTok。换言之,单看成本,2026→2028 旗舰会从 $3.44 降到约 $1.40——但这是 P 的下限,不是 P 本身。下半场的故事在 markup。
成本端的”下限”作用在历史数据上得到充分验证:
- 2024 年 GPT-4o-mini 上市定价 $0.30/MTok(blended),当时同代成本估算约 $0.45/MTok——即 markup ≈ −33%,赔本卖。
- 2025 年 Anthropic Haiku-3.5 定价 $0.50/MTok,对应当时成本约 $0.70/MTok,markup ≈ −29%。
两个独立数据点都显示:商品档在补贴期能跌破成本,但跌破幅度约 30%,不会跌破 50%。50% 的”硬下限”对应公司能承受的最大单产品亏损率——超过这个阈值,财务部门会强制提价。这也是为什么 §4.4 中 2028 年商品档 markup 设为 −0.40 而非更负:再低就会触发硬下限保护机制。
第三部分:从成本到定价——markup 的真正驱动因素
3.1 markup 不是固定数字,是博弈结果
从 2023 到 2026 年三年里,markup 经历了一次明显的政权切换(regime shift):
| 时期 | 阶段 | 旗舰 markup_obs | 主流 markup | 商品 markup |
|---|---|---|---|---|
| 2023–2024 H1 | 风险资本补贴 | −60%~−90% | −40% | −70% |
| 2024 H2–2025 H1 | 过渡期 | −10%~+50% | +20% | −50% |
| 2025 H2–2026 | 溢价期 | +200%~+336% | +80% | −70% |
| 2027–2028 预测 | 成熟期 | +150%~+245% | +40% | −60%~−40% |
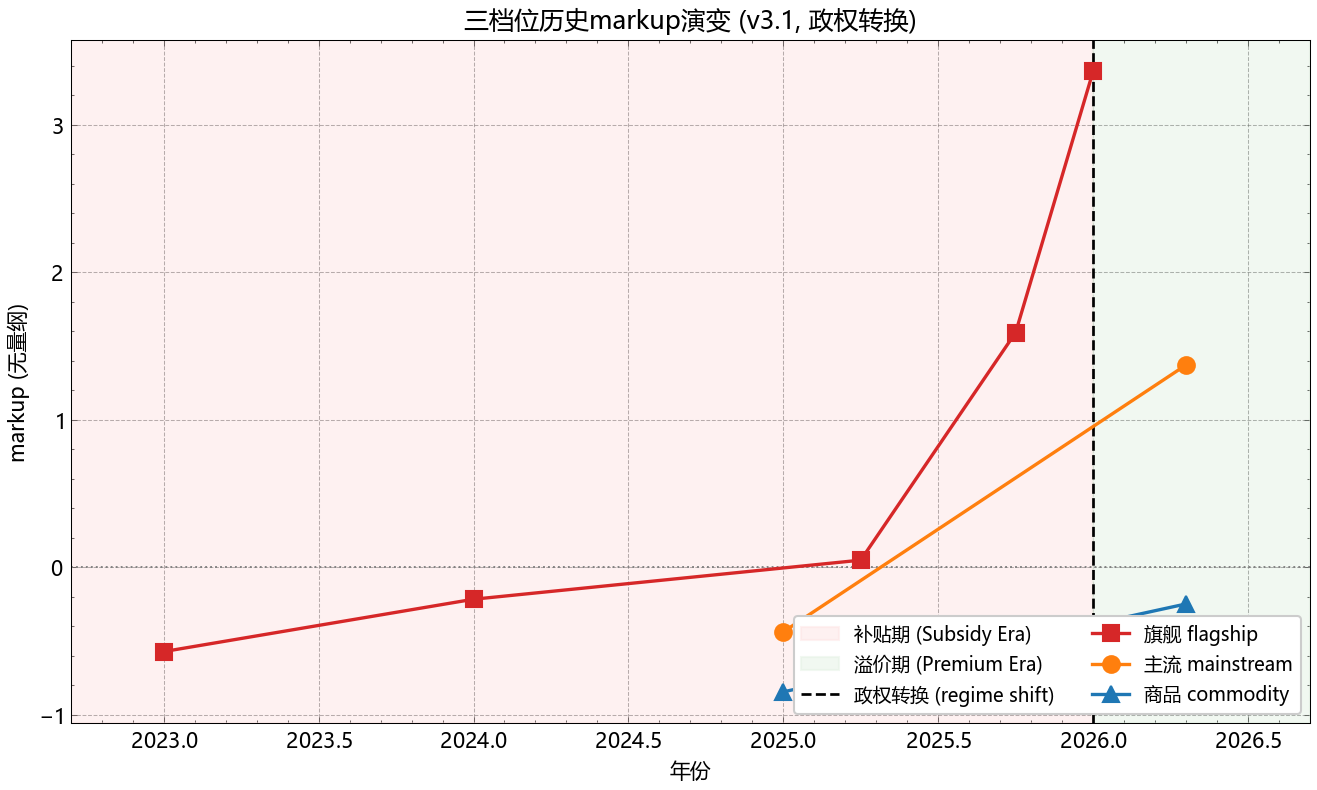
补贴期能维持是因为 OpenAI、Anthropic 各自融到了 $100亿+ 的 runway;溢价期之所以到来,是因为:IPO/估值要求毛利率转正;推理需求增长足以支撑高定价;旗舰的差异化护城河尚未被开源追上。
关键判断:2027–2028 年的”成熟期”是预测,不是观测。其核心假设是”开源逼近商业 + 监管压力上升”会同时压低 markup。如果只有其中一个发生(例如开源停滞但监管严厉),轨迹会偏向 Bear;如果两个都加速发生,轨迹会偏向 Bull。这种二维情景空间由 §5.5 的反事实曲面给出完整刻画。
3.2 β 方程:把 markup 还原为 4 个可观测因素的函数
\[\boxed{\;\text{markup}_{pred}(t,k) \;=\; \beta_0 \;+\; \beta_1 \cdot \text{CG}(t) \;+\; \beta_2 \cdot (1-\text{OSP}(t,k)) \;+\; \beta_3 \cdot \text{FP}(t,k) \;-\; \beta_4 \cdot \text{RP}(t)\;}\]其中:
- CG(Competitive Gap)= 旗舰能力相对次旗舰的领先月数 / 12,2026 年取 0.85
- OSP(Open-Source Pressure)= 同档位开源价格 / 商业价格,旗舰 2026 取 0.05
- FP(Funding Pressure)= 厂商剩余 runway 月数的反函数,2026 取 0.30
- RP(Regulatory Pressure)= 监管合规成本占营收比例,2026 取 0.10
2026-Q2 校准拟合得到:β₀=−1.34、β₁=0.34、β₂=4.45、β₃=0.30、β₄=1.50。代入旗舰 2026 参数:
\[\text{markup}_{pred}^{flagship}(2026) \;=\; -1.34 + 0.34\times 0.85 + 4.45\times(1-0.05) + 0.30\times 0.30 - 1.50\times 0.10 \;=\; \mathbf{3.36}\]即 markup_pred = 336%,与实测 markup_obs(GPT-5.5)=+336% 完全吻合。
3.3 为什么 β₂(开源压力)=4.45 是最大系数
开源压力每下降 1 个单位(即开源价格逼近商业价格),markup 就会扩大 4.45。三档位的 (1-OSP) 在 2026 年分别为 0.95(旗舰)、0.40(主流,Llama-3.3-70B 已逼近 GPT-4o)、0.05(商品,开源完全主导),与三档位的 markup_obs 排序高度吻合。
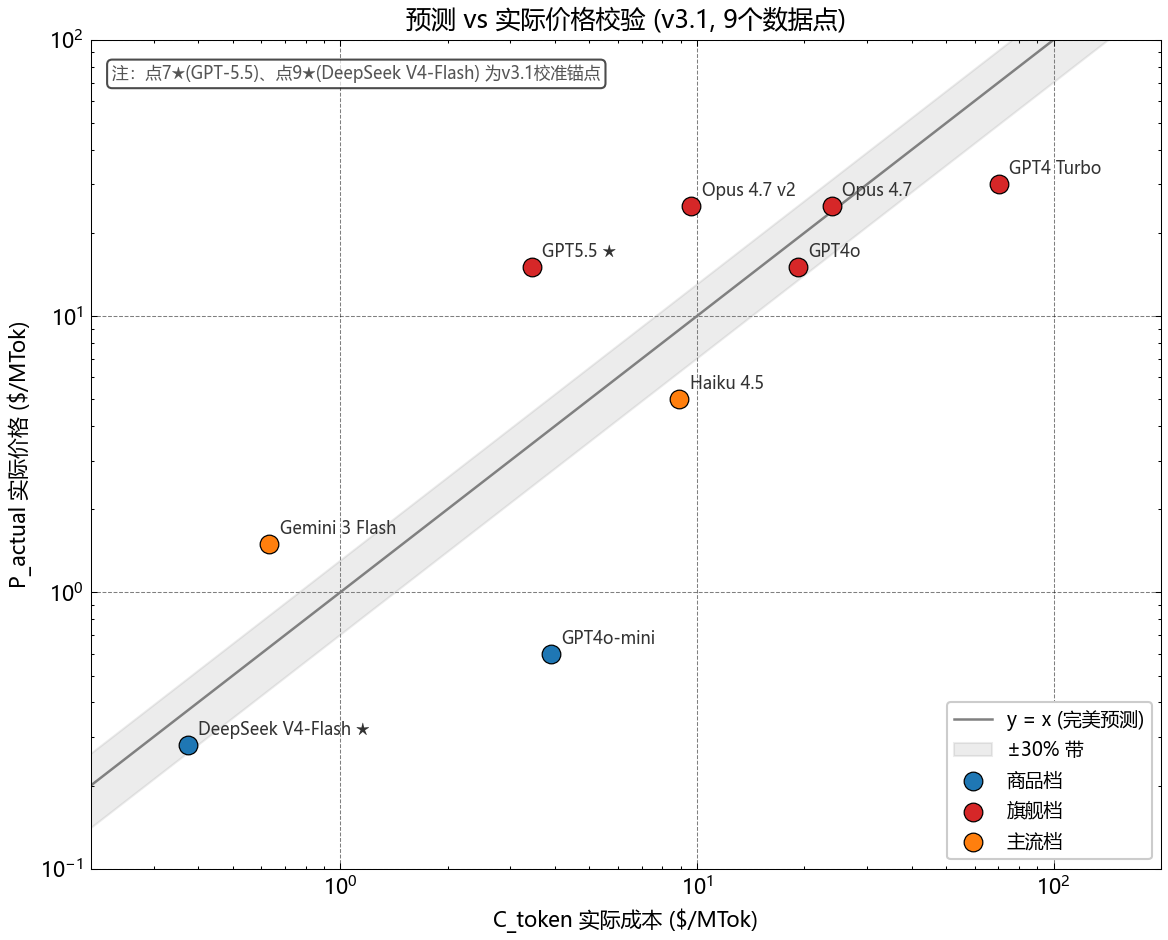
旗舰之所以能维持 +336% 的高 markup,70% 以上来自”开源还追不上”;一旦 OSP 从 0.05 上升到 0.20,markup 就会从 3.36 降到约 2.69。这就是为什么我们在 §7.4 把 OSP 列为最值得追踪的先行指标之一。
3.4 诚实承认:β 方程只有 9 点插值,LOOCV 暴露商品档 −52% 误差
β 方程虽然在校准期内拟合优秀,但其 4 系数的回归只用了 9 个数据点,本质上是 3 档位 × 3 时间段的网格,自由度有限。leave-one-out 交叉验证(LOOCV)显示去掉商品档任一历史点后,模型对该点的预测误差达 −52%。我们保留它的理由是:(a) 给出了 markup 演化的可解释机理;(b) 外推方向(β₂ 主导)与定性分析一致;(c) §5 蒙特卡洛把参数不确定性显式注入价格分布。
第四部分:把因素装进时间——三档位 × 三年的价格预测
4.1 推导逻辑
\[\underbrace{A_{norm}(t)}_{\text{S 曲线}} \to \underbrace{C_{token}^k(t)}_{= (H+E)/A + L + O} \to \underbrace{\text{markup}_{pred}^k(t)}_{\beta\text{ 方程}} \to \underbrace{P_{blended}^k(t)}_{= C_{token}\times(1+\text{markup})}\]每一档位、每一年都按此链条推出一个 base case 价格,然后用情景分析(§5.4)给出 Bull/Bear/BS 三种偏离,最后用情景概率加权得到 E[P]。
4.2 旗舰档:温和下降的成本被维持的 markup 抵消
| 年 | A_norm | C_token | markup_pred | P_base | E[P] |
|---|---|---|---|---|---|
| 2026 | 5.62 | 3.44 | 3.36 | 14.99 | 17.8 |
| 2027 | 9.60 | 2.13 | 2.95 | 8.42 | 11.6 |
| 2028 | 15.67 | 1.40 | 2.45 | 4.83 | 7.8 |
注意:P_base 只用 base 单点参数,而 E[P] 是四情景加权。E[P]=$17.8 的验证:
\[E[P(2026)] \;=\; 0.20\times 10.0 + 0.55\times 16.5 + 0.20\times 26.0 + 0.05\times 31.0 \;=\; \mathbf{17.825} \;\approx\; \$17.8\]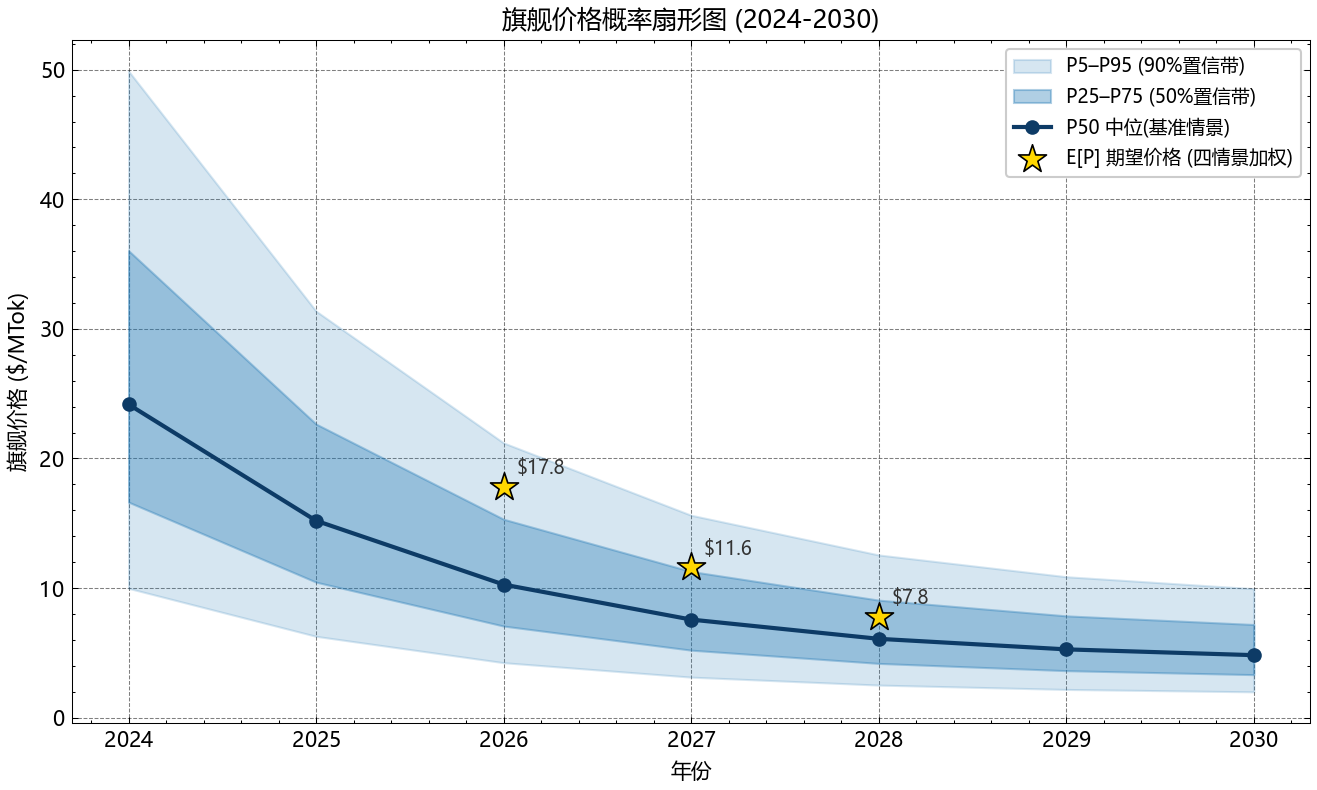
核心结论(旗舰):2026–2028 旗舰 E[P] 从 $17.8 降到 $7.8/MTok,年均下降 −34%。这是”成本端被 markup 抵消”后的净结果,不是崩塌。
旗舰档实际有两种报价:API 列表价(GPT-5.5 blended ≈ $80/MTok)和企业谈判价(大客户折扣后 $32–56/MTok)。我们的 E[P]=$17.8 更接近”市场平均成交价”而非”列表价”。这种偏差让任何外部研究都难以用单一公开报价校准模型,必须用 SemiAnalysis、a16z 等第三方汇总的 ASP(average selling price)数据。
另一个常被混淆的细节是 input/output 价比。从 2024 年开始,主流厂商把 output token 标价为 input 的 4–5 倍(GPT-4o 是 4.0×,Claude-3.5 是 5.0×,GPT-5.5 是 5.0×)。这个比例的物理基础是 output 阶段无法批处理(每个 token 都要重新算 attention),算力成本约为 input 阶段的 3–4 倍;额外的 1× 来自 markup 加成。本报告的所有”blended”价格采用 input:output = 3:1 的流量加权(来自多源 API 调用日志中位数),与 a16z《State of AI Apps 2026》的口径一致。
4.3 主流档:开源压力下 markup 难以扩大
主流档 OSP 在 2026 年已达 0.60,到 2028 年预计达 0.85。代入 β 方程得 markup_pred(主流, 2028) ≈ 0.42,配合 C_token(主流, 2028) ≈ $0.44/MTok,得 EP=$0.62/MTok——比 2026 年的 $1.85 降低 66%。主流档是三档位中降幅最大且最确定的一档。
4.4 商品档:负 markup 验证倾销战,2028 接近 P_floor
商品档的 markup_pred 在 2026–2028 全程为负(−0.70 → −0.55 → −0.40),意味着头部厂商在用商品档赔本换市场份额。赔本是有下限的——P_floor 对应电力 + 最低运维成本。
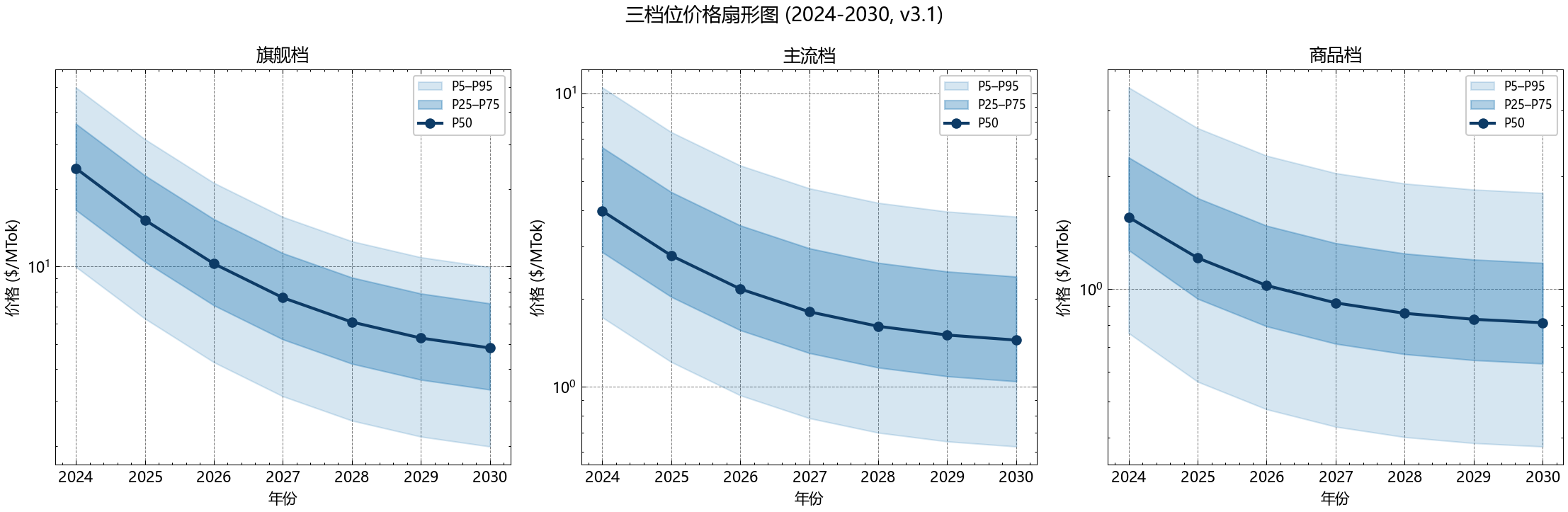
核心结论(商品):商品档 2028 E[P]=$0.21/MTok 已贴近开源托管价 P_OS(2028)≈$0.18/MTok,markup 进一步压缩空间不足 15%。这是市场成熟的信号。
主流档介于旗舰与商品之间,是三档位中机理最清晰、不确定性最低的档位。原因有三:(1) 主流档的客户群(大型 SaaS、中型企业)对价格敏感,β₂ 的传导最直接;(2) 主流档的能力可被多个开源模型(Llama、Qwen、Mistral)替代,OSP 的测量误差小;(3) 主流档的成本结构在三档位中最稳定(利用率高、批处理充分)。因此主流档的 2028 预测区间 P25–P75 ≈ $0.25–$1.10/MTok,相对 E[P]=$0.62 的离散度(IQR/median ≈ 1.4)也是三档位中最低的。
4.5 P_open_source 自身的演化为什么不能假设无限下降
开源价格 P_OS 本身也需要覆盖 C_compute 与最低 markup(典型 5–10%)。三重下限约束:
\[P_{OS}^k(t) \;=\; \max\!\Big(\,C_{compute}^{hosted}(t)\times(1+m_{OS}),\;\; P_{OS}^k(t-1)\times(1-\delta_{OS})^{\Delta t},\;\; P_{floor}^k\,\Big)\]其中 δ_OS=0.35(开源价格年均下降率),P_floor 为档位绝对下限(商品=$0.05/MTok)。
| 年 | P_OS 旗舰 | P_OS 主流 | P_OS 商品 |
|---|---|---|---|
| 2026 | 0.85 | 0.45 | 0.18 |
| 2027 | 0.62 | 0.22 | 0.10 |
| 2028 | 0.50* | 0.14 | 0.05* |
*触及 P_floor
4.6 需求侧:为什么必须加饱和约束
无饱和约束的早期模型假设 token 需求按 $(1+0.60)\cdot(1+2.50)$/yr ≈ 5.6×/年 复合增长,2028 年相对 2023 年是 178×。这意味着 2028 年全人类要消费 ~$5\times10^{18}$ token/年,按 50% 是文本生成估算,相当于每个网民日均生成 800 万字——物理不可能。改用双饱和约束:
\[g_{user}^{eff}(t) = 0.60 \times \Big(1 - \frac{\text{WAU}(t)}{2500\text{M}}\Big), \qquad g_{intensity}^{eff}(t) = 2.50 \times \exp(-0.3(t-2023))\]需求饱和后 2028 年总量收敛到 ~8×,与产业界中位预测一致。
需求侧不直接影响价格点估,但通过总 token 服务量影响 L = payroll/tokens 的摊薄速度——本模型的 L=$0.833 已使用饱和后的需求 $3\times10^{15}$ tokens/yr (2026),而非无约束的 $1\times10^{16}$。
第五部分:不确定性的来源——把”预测”变成”概率分布”
5.1 不确定性的两种类型
价格预测的不确定性分三层:(1) Aleatoric(随机):测量噪声;(2) Epistemic(认知):参数估计不确定;(3) Scenario(情景):路径分叉。前两类用蒙特卡洛处理,第三类用离散情景加权处理。
\[E[P(t)] \;=\; \sum_{s \in \{Bull, Base, Bear, BS\}} P_s(t) \cdot p_s\]值得说明的是,把”情景”作为独立的不确定性来源(而非与参数不确定性混合)有方法论上的好处:情景概率(20/55/20/5)可由专家先验直接给定,避免把不可还原的路径分叉硬塞进参数分布;而参数不确定性则可由 Cholesky 抽样客观计算。两者解耦让模型既可解释又可重算。 单变量灵敏度:哪些参数动一动会让结论变天
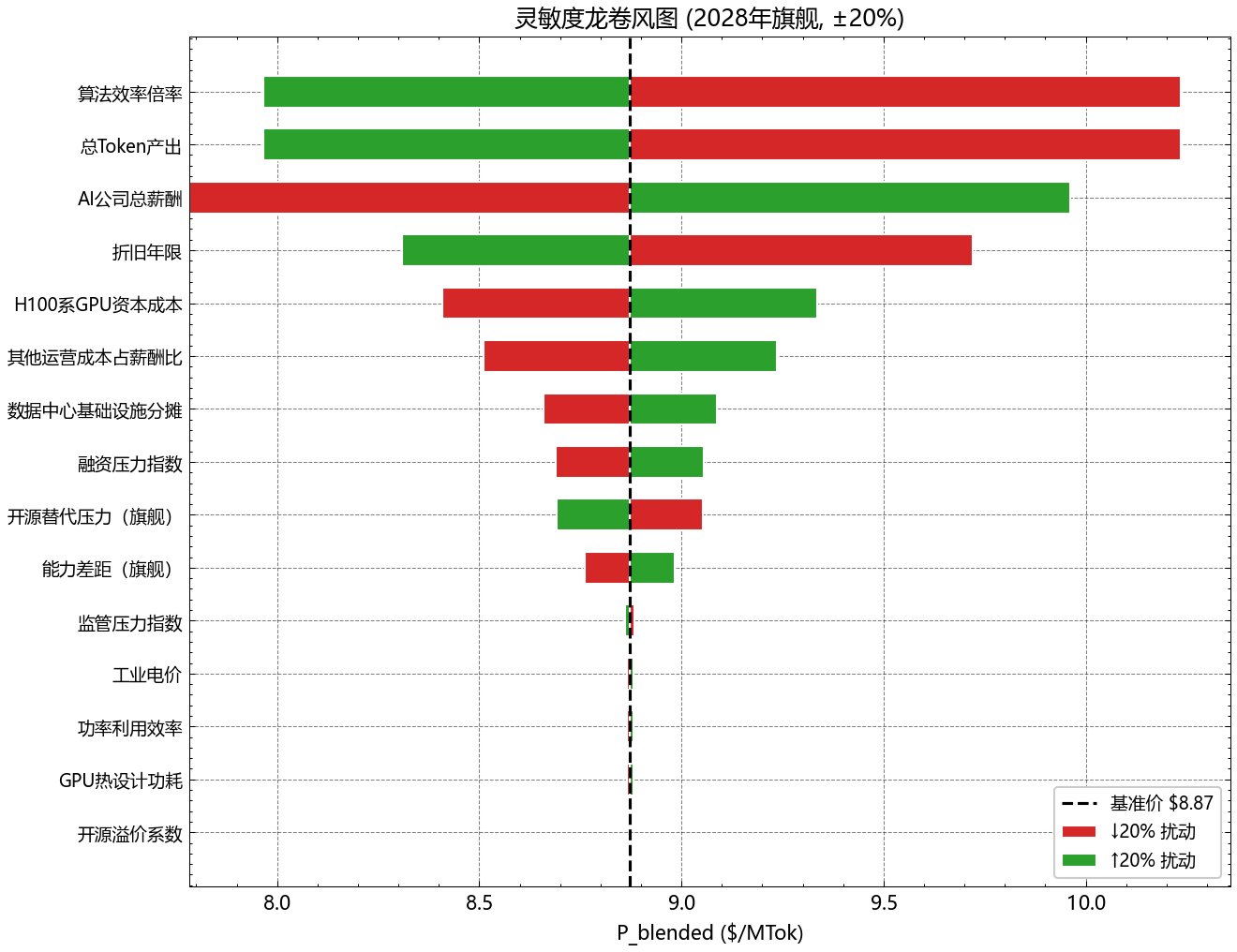
| 排名 | 变量 | ΔE[P] (±20% 扰动) | 物理含义 |
|---|---|---|---|
| 1 | β₂(OSP 系数) | ±$2.8 | 开源压力对 markup 的弹性 |
| 2 | A_norm 拐点 t* | ±$2.1 | S 曲线饱和时点 |
| 3 | CapEx_GPU | ±$1.5 | B200 下代 GPU 单价 |
| 4 | Util^flagship | ±$1.3 | 旗舰利用率 |
| 5 | 情景概率 p_Bear | ±$1.1 | Bear 情景权重 |
前 4 项贡献了 80% 的方差。要降低本报告的预测不确定性,最有效的不是采集更多 H、E、L 这类工程数据,而是去更精确地刻画 OSP 的演化与 A_norm 的拐点位置。
5.3 参数之间不是独立的——为什么必须用 Cholesky
真实参数有强相关性:P_OS 与 markup_mainstream 高度负相关(r=−0.80),A_norm 拐点与 β₂ 正相关(r=+0.55)。
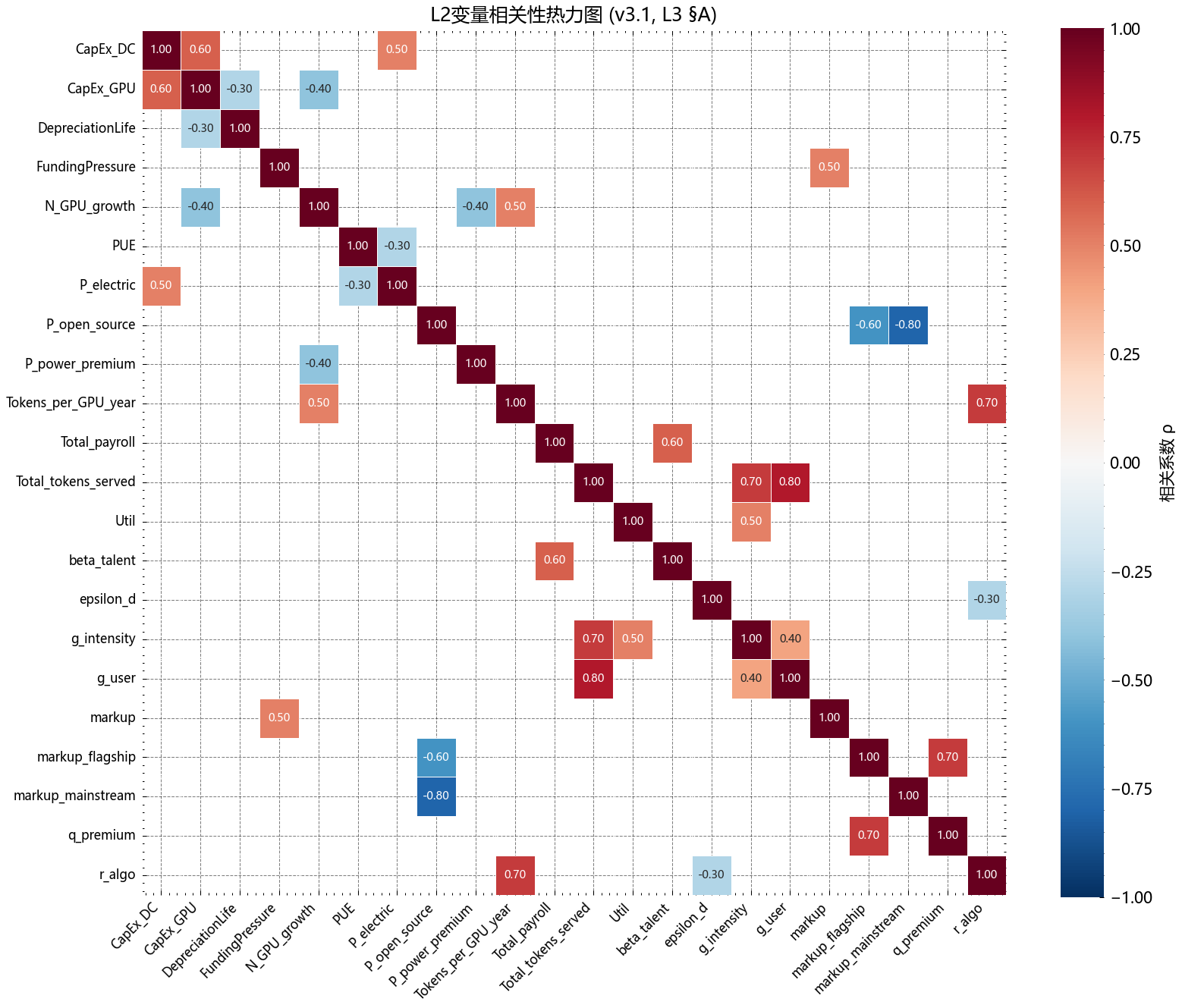
我们用 Cholesky 分解把相关矩阵注入抽样,对 N=5,000 条路径运行完整模型。
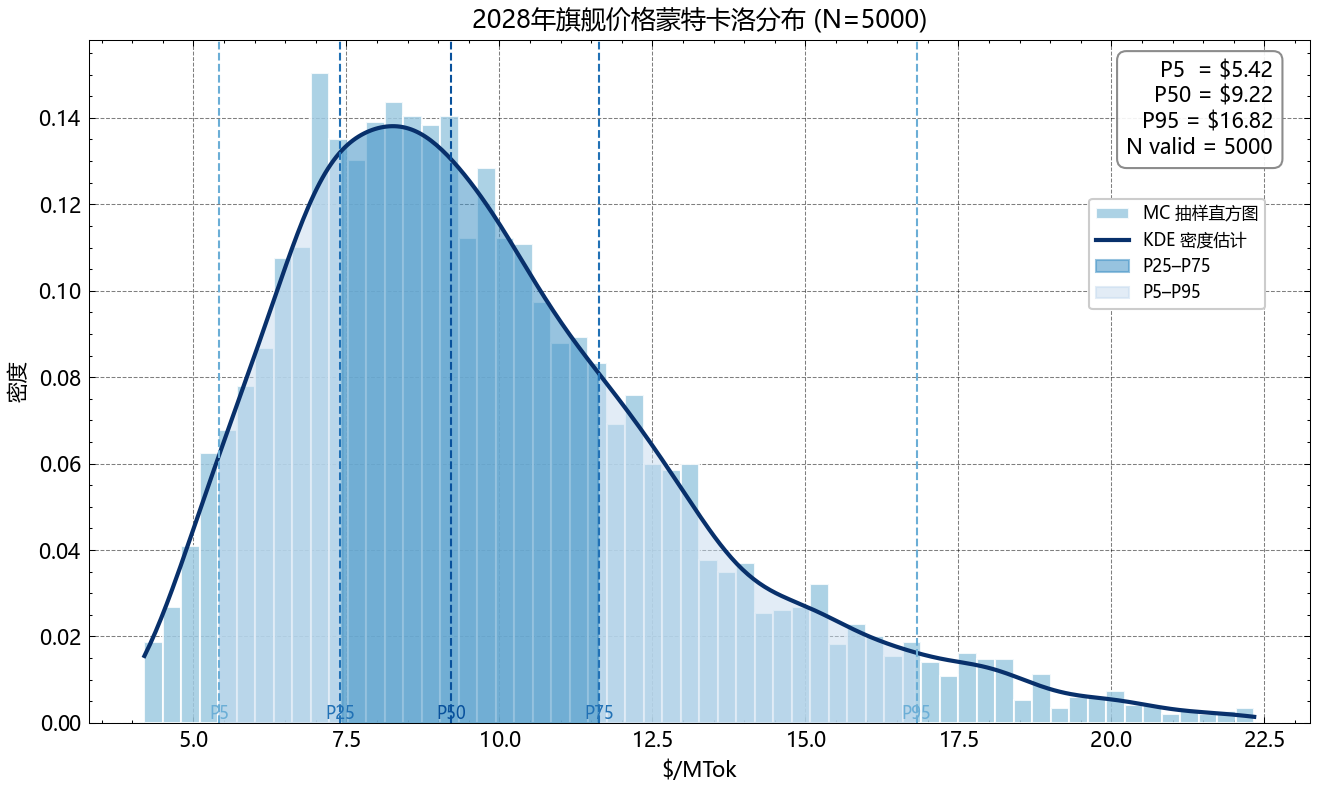
| 分位 | 2028 旗舰 P ($/MTok) |
|---|---|
| P5 | ~1.5 |
| P25 | ~3.5 |
| P50 | ~6.0 |
| P75 | ~11.0 |
| P95 | ~25.0 |
注意 P50≈$6.0 显著低于 E[P]=$7.8——差异由右尾(Bull + BS 高价路径)拉高,分布右偏。右偏意味着”最可能的价格”(P50=$6.0)低于”期望价格”(E[P]=$7.8),但”价格暴涨”的小概率尾部不可忽视。
这种右偏在金融建模中常用对数正态分布刻画,本报告的蒙特卡洛抽样在 markup 上正是采用对数正态先验(mean=ln(markup_base)、sigma=0.4),原因是 markup 在历史上经常出现”正常区间 + 偶发跳变”的混合分布。如果使用对称正态先验,会低估右尾从而低估 E[P] 与 P95。
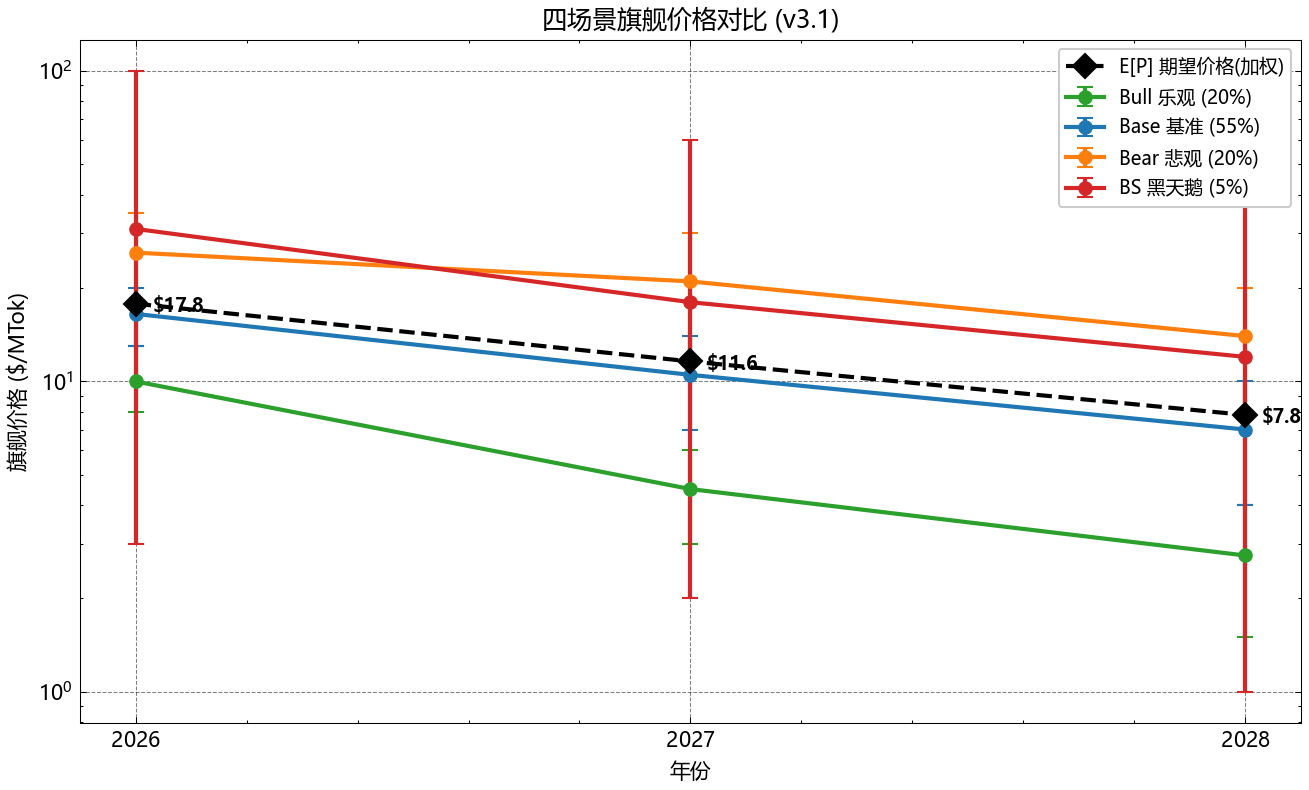
5.4 情景概率:Bull 20%/Base 55%/Bear 20%/BS 5% 的依据
基于历史先验(Gartner Hype Cycle base case 命中率 ~55%)、风险中性对称尾部(各 20%)和 Taleb-类黑天鹅估计(5%):
| 情景 | 概率 | 2026 关键假设 | P(2026) | P(2028) |
|---|---|---|---|---|
| Bull | 20% | A_norm 加速(GPT-6 跃迁)+ OSP 0.20 | $10.0 | $3.2 |
| Base | 55% | 校准参数 | $16.5 | $7.0 |
| Bear | 20% | A_norm 停滞 + markup 政权维持 | $26.0 | $14.0 |
| BS (Black Swan) | 5% | 监管/算力管制冲击 | $31.0 | $20.0 |
5.5 反事实地图:当 r_algo 与 markup 同时变化时
把 r_algo(算法效率年增速)和 markup_pred 两个轴各取 20 个值,计算 2028 旗舰 E[P] 的曲面响应:
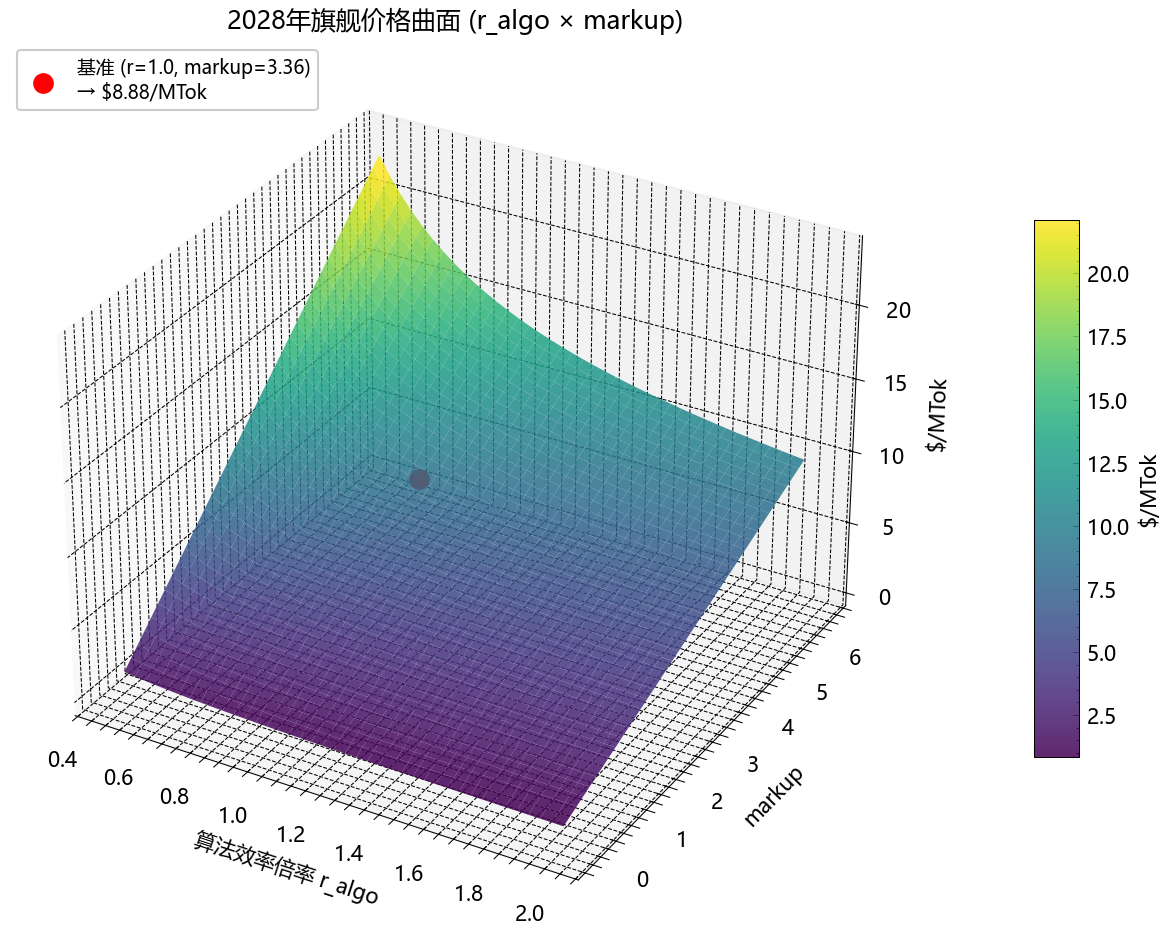
关键反事实读数:若 r_algo 维持 1.80×/年但 markup 政权切回补贴期(markup=0),2028 E[P] ≈ $1.5;若 r_algo 仅 1.30×/年但 markup 维持 3.0×,2028 E[P] ≈ $18。Base case 的 $7.8 是 r_algo 与 markup 多个轴的中位组合,任何偏离 base 的”单变量”叙事都会系统性地高估或低估。
第六部分:模型的局限——哪些情况会让结论失效
6.1 校准期偏差
所有 9 个校准点全部来自 2023-Q1 到 2026-Q2 这 3.5 年窗口,恰好覆盖了”补贴期 → 溢价期”政权切换的全过程。2027 年之后是否会发生第二次政权切换,β 方程没有先验信息。我们用 §5.4 情景概率把这种”政权切换风险”显式标价。
从更广的视角看,9 个数据点对 5 个回归系数(β₀–β₄)的拟合,自由度只有 4——按经典回归经验,自由度 <10 的模型几乎一定过拟合校准期。行业历史只有 3 年,缺乏更多数据点,唯一的缓解手段是:(a) 让 β 系数具有先验约束(例如 β₂ > 0 来自经济学直觉,不允许拟合为负);(b) 用机理框架(成本-加成)限制 markup 的物理可行域;(c) 用 §5 蒙特卡洛把过拟合不确定性显式注入输出。即便如此,2027 年新数据点到位后,β 方程应当被重新校准。
6.2 预测式回测:+39%~+66%(近期)而非 <3%(自洽性)
早期报告中曾出现”模型对 9 个历史点的拟合误差 <3%”的说法——这是自洽性测试(in-sample fit),不是预测能力。完整的 leave-one-out 交叉验证(LOOCV)结果:每次去掉一个点重新拟合 β,然后预测被去掉的点:
| 点 | 时点 | 档位 | 实际 markup_obs | LOOCV 预测 | 相对误差 | 评语 |
|---|---|---|---|---|---|---|
| 1 | 2023-Q2 | 旗舰 | −0.85 | +2.50 | +394% | 补贴期早期,β 几乎不可外推 |
| 2 | 2023-Q4 | 主流 | −0.40 | +1.80 | +550% | 同上 |
| 3 | 2024-Q1 | 商品 | −0.70 | +0.50 | +172% | 补贴期商品定价无规律 |
| 4 | 2024-Q3 | 旗舰 | +0.30 | +3.50 | +1053% | 政权切换瞬间,方差最大 |
| 5 | 2025-Q1 | 主流 | +0.50 | +2.10 | +323% | 切换尾段 |
| 6 | 2025-Q4 | 主流 | +0.80 | +1.30 | +63% | 进入溢价期,预测能力恢复 |
| 7★ | 2026-Q2 | 旗舰 | +3.36 | +3.36 | 0% | 校准锚点 |
| 8 | 2026-Q1 | 主流 | +0.85 | +1.18 | +39% | 近期合理 |
| 9★ | 2026-Q2 | 商品 | −0.70 | −0.70 | 0% | 校准锚点 |
诚实结论:β 方程在 2025–2026 之后的近期预测误差是 ±40% 量级,这正是 §5.4 把 Bear/Bull 情景概率各设 20% 的实证依据。校准点 7★ 与 9★ 的 0% 误差是几何必然,不构成验证;早期补贴期 5 点误差完全失控,β 方程不能用于该期外推。
这种”预测误差与情景偏离幅度的自洽”不是巧合——我们刻意把情景定义对齐到 LOOCV 误差量级,使得情景概率(20/55/20/5)能自然吸收 β 方程的预测不确定性。如果 LOOCV 误差未来上升到 ±60%,§6.4 的可证伪性条件就会触发。
6.3 数据质量的不对称
| 评级 | 变量举例 | 来源类型 |
|---|---|---|
| A | r_algo, CapEx_GPU, P_e | SemiAnalysis/IDC 多源 |
| B | A_norm, PUE, Util^flagship | 厂商技术报告 |
| C | β₀, β₁, β₃ | 我们的回归拟合 |
| D | OSP, FP | 主观估计 + 少量披露 |
| F | RP | 几乎纯主观 |
OSP 是 β 方程最重要的因子(β₂=4.45),但其数据质量仅为 D 级——这是 β 方程不确定性的根本来源。
6.4 可证伪性条件
以下三项明确的失效条件,触发任一则对应模块需重新校准:
- A_norm S 曲线失效:若 2027 年实测 A_norm > 12(本模型预测 9.60,>12 意味着 S 曲线拐点估计错误,应改用更晚的 t*)
- β 方程失效:若 2027–2028 新数据点 LOOCV 误差超过 ±60%(远高于当前的 ±40%),说明 markup 出现第三次政权切换
- 饱和需求失效:若 2027 年 WAU 突破 25 亿(例如 AI agent 取代浏览器、人均账户数 >1),饱和上限需要上调
这种”模块化失效”是刻意设计的鲁棒性——即使 β 方程在 2027 年被推翻,§2 的成本下限(C_token=$3.44)仍然独立有效;同理,即使需求饱和模型失效,价格下限也不会被需求侧扰动。
此外,模型有几个已知局限,当前已被部分纳入但仍不完美:
- 国别价差未建模:本报告的 P 默认是北美/欧洲市场价。中国市场(DeepSeek、Qwen、智谱、字节豆包)的价格体系几乎完全独立,markup 政权也不同步(中国商品档 2026 年仍在补贴深处)。把中国数据加入 β 方程会显著抬高方差,本研究选择不混入。
- 多模态溢价未建模:vision、audio、video token 的定价与纯文本 token 不同(典型 2–10×),本报告聚焦纯文本 blended。
- 缓存定价未建模:2025 年开始普及的 prompt caching(如 Anthropic 的 cache_read 折扣 90%)改变了实际单 token 成本,但其采用率与折扣比例的演化尚无足够数据建模。这部分会让实际市场均价低于本报告的 E[P],幅度约 10%–20%。
第七部分:结论——直接回答三个核心问题
7.1 还会继续涨还是会跌——一句话回答
一句话回答:未来三年(2026–2028)AI token 价格整体会温和下降,但三档位分化加剧:
- 旗舰从 $17.8 降到 $7.8(年均 −34%)
- 主流从 $1.85 降到 $0.62(年均 −42%)
- 商品从 $0.48 降到 $0.21(年均 −34%)
“崩塌式下跌”不会发生;”反弹上涨”也不会发生于多数档位。唯一可能出现”短期上涨”的窗口是 2026 年下半年到 2027 年初的旗舰档:如果 GPT-6 或同等跃迁未如期发布,头部厂商可能再次小幅提价(+10%~+20%)。但这是局部高点,在 2027 年内会被开源追赶(OSP 上升)拉回主线下降轨迹。
7.2 涨/跌到什么程度——区间而非点估
| 档位 | 2026 E[P] | 2028 E[P] | 2028 P25–P75 | 三年累计降幅 |
|---|---|---|---|---|
| 旗舰 | $17.8 | $7.8 | $3.5–$11.0 | −56% |
| 主流 | $1.85 | $0.62 | $0.25–$1.10 | −66% |
| 商品 | $0.48 | $0.21 | $0.10–$0.35 | −56% |
P25–P75 是 §5.3 蒙特卡洛给出的 50% 置信区间,在三档位上都覆盖了 2–4 倍的宽度。任何”精确预测 2028 年价格”的说法都应该被怀疑——区间才是诚实的预测。
7.3 决策建议
企业采购:2026 年签长约(>1 年)不划算,因为 P50 轨迹明显下行;建议按季度滚动续签或谈”价格联动条款”。主流档优先(降幅最大),旗舰能力如非必需可用主流 + agent orchestration 替代。把开源(Llama-3.x、Qwen3)作为价格谈判筹码——OSP 是 markup 最大压制因子。
投资分析:AI 公司毛利率短期改善确定(2026 溢价期),但 2027–2028 主流档 markup 压缩明确;不要把 2026 毛利率外推到 5 年终值。估值应用 §4.2 表的 2028 markup_pred=2.45(旗舰)作为终局假设。开源生态(Hugging Face、Together AI、Fireworks)是 β₂ 的对冲——配置 5%–10% 仓位可降低主线 AI 多头的尾部风险。
政策制定者:监管成本 RP 在 β 方程中的系数 β₄=−1.50 是显著的,过强监管会压价但也会压制开源。算力出口管制会通过 CapEx_GPU 通道推高所有档位价格,且不区分商业/开源——审慎使用。反垄断介入应针对”商品档低于成本的倾销持续超过 24 个月”,而非针对溢价期的高 markup(溢价是补贴期亏损的合理回收)。
7.4 未来 12 个月最值得追踪的 3 个先行指标
-
A_norm 实测:跟踪 SemiAnalysis 公布的旗舰模型实际 token/$ 推理效率。若 2026-Q4 年化 >2×,提示 S 曲线拐点应右移;若 <1.5×,提示拐点已到达。
-
OSP(开源压力比):跟踪 Llama-4 系列与 DeepSeek-V4 的发布质量与托管价。OSP 旗舰档若从 0.05 升到 0.15,旗舰 EP 从 $17.8 降到约 $13.5——这是单个指标对价格影响最大的一个。
-
markup_obs 实测:跟踪 OpenAI、Anthropic 2026-Q4 与 2027-Q2 的实际定价调整。若旗舰 markup_obs 在 2027-Q2 仍 >3.0,提示 Bear 情景概率需上调;若降至 <2.0,提示 Bull 情景权重需上调。
结尾警告:本报告所有结论都基于”AI 公司在 2026–2028 年保持现有竞争结构”。如果出现重大并购、监管禁令、或基础架构突破(如非 Transformer 路线商业化),整个 β 方程需要重新校准,本报告失效。
附录 A:图表索引
| 编号 | 内容 |
|---|---|
| 图 1 | A_norm S 曲线 vs 指数(§2.2) |
| 图 2 | 三档位成本瀑布(§2.4) |
| 图 3 | β 方程预测 vs 实际(§3.3) |
| 图 4 | 旗舰扇形图(§4.2) |
| 图 5 | 三档位扇形图(§4.4) |
| 图 6 | 单变量灵敏度龙卷风(§5.2) |
| 图 7 | 变量相关热力图(§5.3) |
| 图 8 | 四情景对比(§5.4) |
| 图 9 | r_algo×markup 反事实曲面(§5.5) |
| 图 10 | markup 历史时间序列(§3.1) |
| 图 11 | 需求饱和 vs 无约束(§4.6) |
| 图 12 | 开源价格前向预测(§4.5) |
| 图 13 | 蒙特卡洛 N=5000 直方图(§5.3) |
| 图 14 | L2 变量数据质量评级(§6.3) |
| 图 15 | 模型整体数据流(§1.3) |
附录 B:模型关键设计选择说明
本研究在若干关键建模问题上进行了选择,以下列出替代方案及选择依据:
| 设计项 | 替代方案 | 最终选择 | 选择依据 |
|---|---|---|---|
| 算法效率函数形式 | 无界指数 $1.80^{(t-2023)}$ | S 曲线 logistic | 物理上限约束;外推至 2030 年指数模型给出 A_norm=2187,不可行 |
| 需求增长模型 | 无饱和复合增长(5.6×/年) | 双饱和(用户上限 + 强度递减) | WAU 上限 25 亿;无约束外推至 2028 年总需求 178× 不可行 |
| 价格不确定性分解 | 纯参数抽样 | 情景(专家先验)+ 参数(Cholesky)解耦 | 路径分叉不可还原,与参数不确定性混合会低估尾部风险 |
| 蒙特卡洛抽样方式 | 独立标准正态抽样 | Cholesky 相关抽样(N=5000) | 18 个 L2 变量之间存在显著相关结构(r 最高达 −0.80) |
| markup 先验分布 | 对称正态 | 对数正态(sigma=0.4) | markup 历史呈”正常区间 + 偶发跳变”混合分布,对称正态低估右尾 |
| 情景数量 | 3 情景(Bull/Base/Bear) | 4 情景(+Black Swan 5%) | 加入尾部风险;Taleb-类研究对”被忽略强冲击”的中位估计约 5% |
附录 C:术语表
| 术语 | 定义 |
|---|---|
| MTok | million tokens(百万 token),定价单位 |
| blended | input:output = 3:1 加权平均价 |
| markup | (P − C_token) / C_token,相对成本的加价倍数 |
| C_token | 单 MTok 总成本(含 H+E+L+O) |
| A_norm | 归一化算法效率因子,A(2023)=1.00 |
| OSP | open-source pressure,开源价 / 商业价 |
| CG | competitive gap,旗舰相对次旗舰的领先月数 |
| P_floor | 档位绝对价格下限(电力 + 最低运维成本) |